mirror of
https://github.com/YaoFANGUK/video-subtitle-remover.git
synced 2026-05-18 11:37:35 +08:00
136 lines
5.2 KiB
Markdown
136 lines
5.2 KiB
Markdown
# STTN for Video Inpainting
|
||

|
||
|
||
### [Paper](https://arxiv.org/abs/2007.10247) | [Project](https://sites.google.com/view/1900zyh/sttn) | [Slides](https://drive.google.com/file/d/1y09-SLcTadqpuDDLSzFdtr3ymGbjrmyi/view?usp=sharing) |[BibTex](https://github.com/researchmm/STTN#citation)
|
||
|
||
Learning Joint Spatial-Temporal Transformations for Video Inpainting<br>
|
||
|
||
[Yanhong Zeng](https://sites.google.com/view/1900zyh), [Jianlong Fu](https://jianlong-fu.github.io/), and [Hongyang Chao](https://scholar.google.com/citations?user=qnbpG6gAAAAJ&hl).<br>
|
||
In ECCV 2020.
|
||
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Citation
|
||
If any part of our paper and repository is helpful to your work, please generously cite with:
|
||
```
|
||
@inproceedings{yan2020sttn,
|
||
author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang,
|
||
title = {Learning Joint Spatial-Temporal Transformations for Video Inpainting},
|
||
booktitle = {The Proceedings of the European Conference on Computer Vision (ECCV)},
|
||
year = {2020}
|
||
}
|
||
```
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Introduction
|
||
High-quality video inpainting that completes missing regions in video frames is a promising yet challenging task.
|
||
|
||
In this paper, we propose to learn a joint Spatial-Temporal Transformer Network (STTN) for video inpainting. Specifically, we simultaneously fill missing regions in all input frames by the proposed multi-scale patch-based attention modules. STTN is optimized by a spatial-temporal adversarial loss.
|
||
|
||
To show the superiority of the proposed model, we conduct both quantitative and qualitative evaluations by using standard stationary masks and more realistic moving object masks.
|
||
|
||
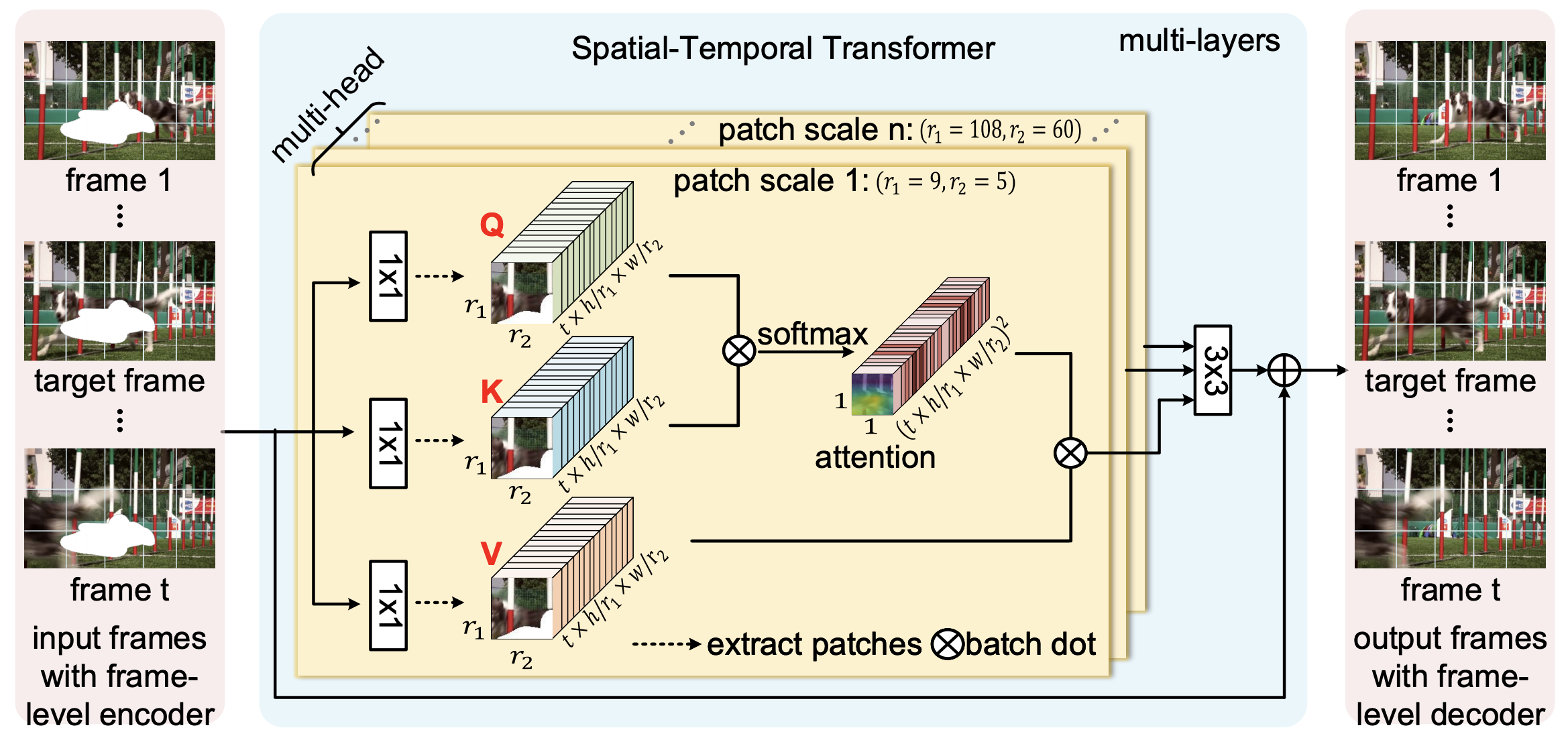
|
||
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Installation
|
||
|
||
Clone this repo.
|
||
|
||
```
|
||
git clone git@github.com:researchmm/STTN.git
|
||
cd STTN/
|
||
```
|
||
|
||
We build our project based on Pytorch and Python. For the full set of required Python packages, we suggest create a Conda environment from the provided YAML, e.g.
|
||
|
||
```
|
||
conda env create -f environment.yml
|
||
conda activate sttn
|
||
```
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Completing Videos Using Pretrained Model
|
||
|
||
The result videos can be generated using pretrained models.
|
||
For your reference, we provide a model pretrained on Youtube-VOS([Google Drive Folder](https://drive.google.com/file/d/1ZAMV8547wmZylKRt5qR_tC5VlosXD4Wv/view?usp=sharing)).
|
||
|
||
1. Download the pretrained models from the [Google Drive Folder](https://drive.google.com/file/d/1ZAMV8547wmZylKRt5qR_tC5VlosXD4Wv/view?usp=sharing), save it in ```checkpoints/```.
|
||
|
||
2. Complete videos using the pretrained model. For example,
|
||
|
||
```
|
||
python test.py --video examples/schoolgirls_orig.mp4 --mask examples/schoolgirls --ckpt checkpoints/sttn.pth
|
||
```
|
||
The outputs videos are saved at ```examples/```.
|
||
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Dataset Preparation
|
||
|
||
We provide dataset split in ```datasets/```.
|
||
|
||
**Preparing Youtube-VOS (2018) Dataset.** The dataset can be downloaded from [here](https://competitions.codalab.org/competitions/19544#participate-get-data). In particular, we follow the standard train/validation/test split (3,471/474/508). The dataset should be arranged in the same directory structure as
|
||
|
||
```
|
||
datasets
|
||
|- youtube-vos
|
||
|- JPEGImages
|
||
|- <video_id>.zip
|
||
|- <video_id>.zip
|
||
|- test.json
|
||
|- train.json
|
||
```
|
||
|
||
**Preparing DAVIS (2018) Dataset.** The dataset can be downloaded from [here](https://davischallenge.org/davis2017/code.html). In particular, there are 90 videos with densely-annotated object masks and 60 videos without annotations. The dataset should be arranged in the same directory structure as
|
||
|
||
```
|
||
datasets
|
||
|- davis
|
||
|- JPEGImages
|
||
|- cows.zip
|
||
|- goat.zip
|
||
|- Annoatations
|
||
|- cows.zip
|
||
|- goat.zip
|
||
|- test.json
|
||
|- train.json
|
||
```
|
||
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Training New Models
|
||
Once the dataset is ready, new models can be trained with the following commands. For example,
|
||
|
||
```
|
||
python train.py --config configs/youtube-vos.json --model sttn
|
||
```
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Testing
|
||
|
||
Testing is similar to [Completing Videos Using Pretrained Model](https://github.com/researchmm/STTN#completing-videos-using-pretrained-model).
|
||
|
||
```
|
||
python test.py --video examples/schoolgirls_orig.mp4 --mask examples/schoolgirls --ckpt checkpoints/sttn.pth
|
||
```
|
||
The outputs videos are saved at ```examples/```.
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Visualization
|
||
|
||
We provide an example of visualization attention maps in ```visualization.ipynb```.
|
||
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Training Monitoring
|
||
|
||
We provide traning monitoring on losses by running:
|
||
```
|
||
tensorboard --logdir release_mode
|
||
```
|
||
|
||
<!-- ---------------------------------------------- -->
|
||
## Contact
|
||
If you have any questions or suggestions about this paper, feel free to contact me (zengyh7@mail2.sysu.edu.cn).
|