mirror of
https://github.com/YaoFANGUK/video-subtitle-remover.git
synced 2026-02-21 09:14:49 +08:00
cli版字幕去除
This commit is contained in:
File diff suppressed because one or more lines are too long
12
backend/inpaint/sttn/.gitignore
vendored
12
backend/inpaint/sttn/.gitignore
vendored
@@ -1,12 +0,0 @@
|
||||
*/__pycache__/
|
||||
release_model
|
||||
*.log
|
||||
debug.py
|
||||
*.avi
|
||||
.ipynb_checkpoints
|
||||
*.DS_Store
|
||||
checkpoints
|
||||
examples/*_result.mp4
|
||||
*.jpg
|
||||
*.png
|
||||
*.zip
|
||||
@@ -1,135 +0,0 @@
|
||||
# STTN for Video Inpainting
|
||||

|
||||
|
||||
### [Paper](https://arxiv.org/abs/2007.10247) | [Project](https://sites.google.com/view/1900zyh/sttn) | [Slides](https://drive.google.com/file/d/1y09-SLcTadqpuDDLSzFdtr3ymGbjrmyi/view?usp=sharing) |[BibTex](https://github.com/researchmm/STTN#citation)
|
||||
|
||||
Learning Joint Spatial-Temporal Transformations for Video Inpainting<br>
|
||||
|
||||
[Yanhong Zeng](https://sites.google.com/view/1900zyh), [Jianlong Fu](https://jianlong-fu.github.io/), and [Hongyang Chao](https://scholar.google.com/citations?user=qnbpG6gAAAAJ&hl).<br>
|
||||
In ECCV 2020.
|
||||
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Citation
|
||||
If any part of our paper and repository is helpful to your work, please generously cite with:
|
||||
```
|
||||
@inproceedings{yan2020sttn,
|
||||
author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang,
|
||||
title = {Learning Joint Spatial-Temporal Transformations for Video Inpainting},
|
||||
booktitle = {The Proceedings of the European Conference on Computer Vision (ECCV)},
|
||||
year = {2020}
|
||||
}
|
||||
```
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Introduction
|
||||
High-quality video inpainting that completes missing regions in video frames is a promising yet challenging task.
|
||||
|
||||
In this paper, we propose to learn a joint Spatial-Temporal Transformer Network (STTN) for video inpainting. Specifically, we simultaneously fill missing regions in all input frames by the proposed multi-scale patch-based attention modules. STTN is optimized by a spatial-temporal adversarial loss.
|
||||
|
||||
To show the superiority of the proposed model, we conduct both quantitative and qualitative evaluations by using standard stationary masks and more realistic moving object masks.
|
||||
|
||||
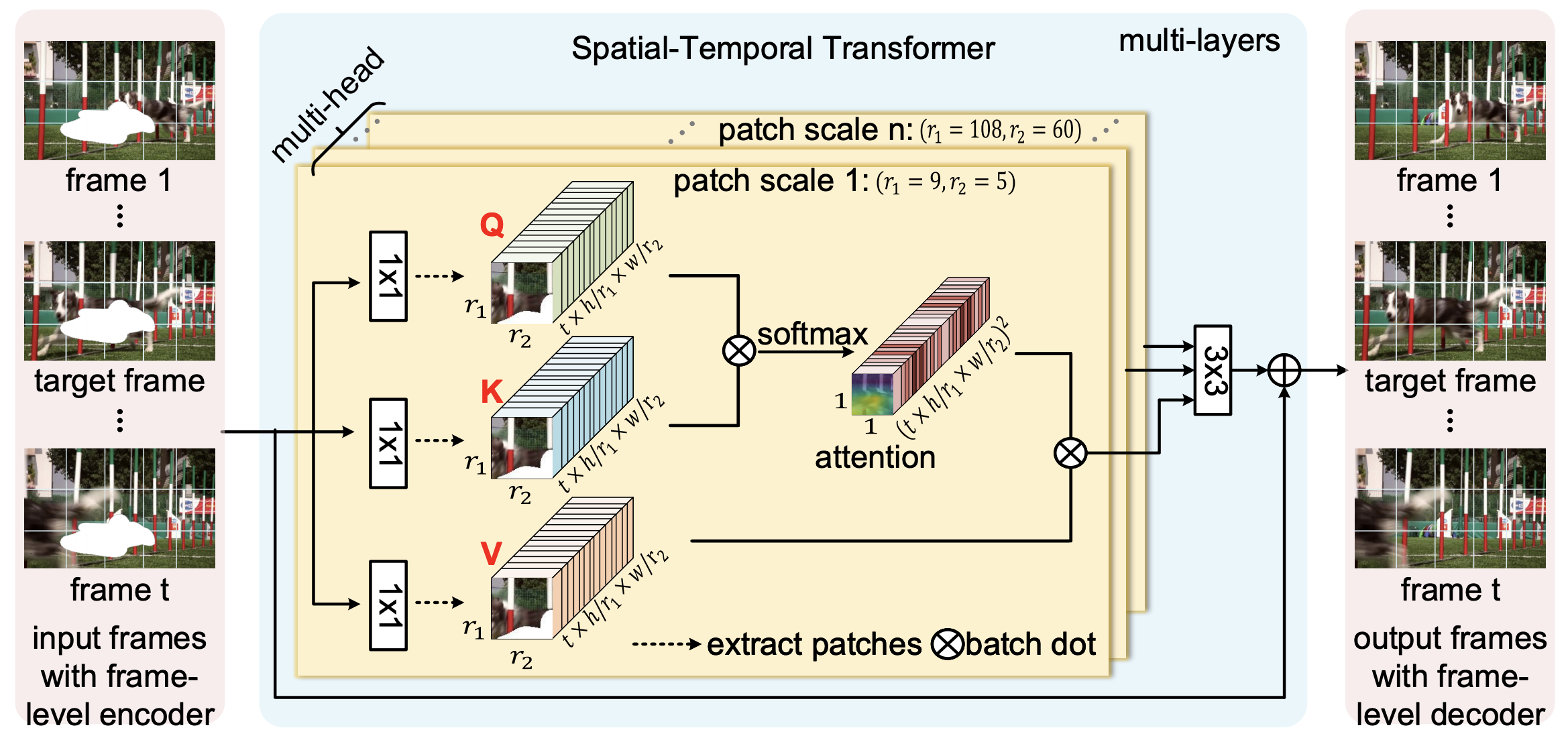
|
||||
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Installation
|
||||
|
||||
Clone this repo.
|
||||
|
||||
```
|
||||
git clone git@github.com:researchmm/STTN.git
|
||||
cd STTN/
|
||||
```
|
||||
|
||||
We build our project based on Pytorch and Python. For the full set of required Python packages, we suggest create a Conda environment from the provided YAML, e.g.
|
||||
|
||||
```
|
||||
conda env create -f environment.yml
|
||||
conda activate sttn
|
||||
```
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Completing Videos Using Pretrained Model
|
||||
|
||||
The result videos can be generated using pretrained models.
|
||||
For your reference, we provide a model pretrained on Youtube-VOS([Google Drive Folder](https://drive.google.com/file/d/1ZAMV8547wmZylKRt5qR_tC5VlosXD4Wv/view?usp=sharing)).
|
||||
|
||||
1. Download the pretrained models from the [Google Drive Folder](https://drive.google.com/file/d/1ZAMV8547wmZylKRt5qR_tC5VlosXD4Wv/view?usp=sharing), save it in ```checkpoints/```.
|
||||
|
||||
2. Complete videos using the pretrained model. For example,
|
||||
|
||||
```
|
||||
python test.py --video examples/schoolgirls_orig.mp4 --mask examples/schoolgirls --ckpt checkpoints/sttn.pth
|
||||
```
|
||||
The outputs videos are saved at ```examples/```.
|
||||
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Dataset Preparation
|
||||
|
||||
We provide dataset split in ```datasets/```.
|
||||
|
||||
**Preparing Youtube-VOS (2018) Dataset.** The dataset can be downloaded from [here](https://competitions.codalab.org/competitions/19544#participate-get-data). In particular, we follow the standard train/validation/test split (3,471/474/508). The dataset should be arranged in the same directory structure as
|
||||
|
||||
```
|
||||
datasets
|
||||
|- youtube-vos
|
||||
|- JPEGImages
|
||||
|- <video_id>.zip
|
||||
|- <video_id>.zip
|
||||
|- test.json
|
||||
|- train.json
|
||||
```
|
||||
|
||||
**Preparing DAVIS (2018) Dataset.** The dataset can be downloaded from [here](https://davischallenge.org/davis2017/code.html). In particular, there are 90 videos with densely-annotated object masks and 60 videos without annotations. The dataset should be arranged in the same directory structure as
|
||||
|
||||
```
|
||||
datasets
|
||||
|- davis
|
||||
|- JPEGImages
|
||||
|- cows.zip
|
||||
|- goat.zip
|
||||
|- Annoatations
|
||||
|- cows.zip
|
||||
|- goat.zip
|
||||
|- test.json
|
||||
|- train.json
|
||||
```
|
||||
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Training New Models
|
||||
Once the dataset is ready, new models can be trained with the following commands. For example,
|
||||
|
||||
```
|
||||
python train.py --config configs/youtube-vos.json --model sttn
|
||||
```
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Testing
|
||||
|
||||
Testing is similar to [Completing Videos Using Pretrained Model](https://github.com/researchmm/STTN#completing-videos-using-pretrained-model).
|
||||
|
||||
```
|
||||
python test.py --video examples/schoolgirls_orig.mp4 --mask examples/schoolgirls --ckpt checkpoints/sttn.pth
|
||||
```
|
||||
The outputs videos are saved at ```examples/```.
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Visualization
|
||||
|
||||
We provide an example of visualization attention maps in ```visualization.ipynb```.
|
||||
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Training Monitoring
|
||||
|
||||
We provide traning monitoring on losses by running:
|
||||
```
|
||||
tensorboard --logdir release_mode
|
||||
```
|
||||
|
||||
<!-- ---------------------------------------------- -->
|
||||
## Contact
|
||||
If you have any questions or suggestions about this paper, feel free to contact me (zengyh7@mail2.sysu.edu.cn).
|
||||
@@ -1,33 +0,0 @@
|
||||
{
|
||||
"seed": 2020,
|
||||
"save_dir": "release_model/",
|
||||
"data_loader": {
|
||||
"name": "davis",
|
||||
"data_root": "datasets/",
|
||||
"w": 432,
|
||||
"h": 240,
|
||||
"sample_length": 5
|
||||
},
|
||||
"losses": {
|
||||
"hole_weight": 1,
|
||||
"valid_weight": 1,
|
||||
"adversarial_weight": 0.01,
|
||||
"GAN_LOSS": "hinge"
|
||||
},
|
||||
"trainer": {
|
||||
"type": "Adam",
|
||||
"beta1": 0,
|
||||
"beta2": 0.99,
|
||||
"lr": 1e-4,
|
||||
"d2glr": 1,
|
||||
"batch_size": 8,
|
||||
"num_workers": 2,
|
||||
"verbosity": 2,
|
||||
"log_step": 100,
|
||||
"save_freq": 1e4,
|
||||
"valid_freq": 1e4,
|
||||
"iterations": 50e4,
|
||||
"niter": 30e4,
|
||||
"niter_steady": 30e4
|
||||
}
|
||||
}
|
||||
@@ -1,33 +0,0 @@
|
||||
{
|
||||
"seed": 2020,
|
||||
"save_dir": "release_model/",
|
||||
"data_loader": {
|
||||
"name": "youtube-vos",
|
||||
"data_root": "datasets/",
|
||||
"w": 432,
|
||||
"h": 240,
|
||||
"sample_length": 5
|
||||
},
|
||||
"losses": {
|
||||
"hole_weight": 1,
|
||||
"valid_weight": 1,
|
||||
"adversarial_weight": 0.01,
|
||||
"GAN_LOSS": "hinge"
|
||||
},
|
||||
"trainer": {
|
||||
"type": "Adam",
|
||||
"beta1": 0,
|
||||
"beta2": 0.99,
|
||||
"lr": 1e-4,
|
||||
"d2glr": 1,
|
||||
"batch_size": 8,
|
||||
"num_workers": 2,
|
||||
"verbosity": 2,
|
||||
"log_step": 100,
|
||||
"save_freq": 1e4,
|
||||
"valid_freq": 1e4,
|
||||
"iterations": 50e4,
|
||||
"niter": 15e4,
|
||||
"niter_steady": 30e4
|
||||
}
|
||||
}
|
||||
@@ -1,80 +0,0 @@
|
||||
import os
|
||||
import cv2
|
||||
import io
|
||||
import glob
|
||||
import scipy
|
||||
import json
|
||||
import zipfile
|
||||
import random
|
||||
import collections
|
||||
import torch
|
||||
import math
|
||||
import numpy as np
|
||||
import torchvision.transforms.functional as F
|
||||
import torchvision.transforms as transforms
|
||||
from torch.utils.data import DataLoader
|
||||
from PIL import Image, ImageFilter
|
||||
from skimage.color import rgb2gray, gray2rgb
|
||||
from core.utils import ZipReader, create_random_shape_with_random_motion
|
||||
from core.utils import Stack, ToTorchFormatTensor, GroupRandomHorizontalFlip
|
||||
|
||||
|
||||
class Dataset(torch.utils.data.Dataset):
|
||||
def __init__(self, args: dict, split='train', debug=False):
|
||||
self.args = args
|
||||
self.split = split
|
||||
self.sample_length = args['sample_length']
|
||||
self.size = self.w, self.h = (args['w'], args['h'])
|
||||
|
||||
with open(os.path.join(args['data_root'], args['name'], split+'.json'), 'r') as f:
|
||||
self.video_dict = json.load(f)
|
||||
self.video_names = list(self.video_dict.keys())
|
||||
if debug or split != 'train':
|
||||
self.video_names = self.video_names[:100]
|
||||
|
||||
self._to_tensors = transforms.Compose([
|
||||
Stack(),
|
||||
ToTorchFormatTensor(), ])
|
||||
|
||||
def __len__(self):
|
||||
return len(self.video_names)
|
||||
|
||||
def __getitem__(self, index):
|
||||
try:
|
||||
item = self.load_item(index)
|
||||
except:
|
||||
print('Loading error in video {}'.format(self.video_names[index]))
|
||||
item = self.load_item(0)
|
||||
return item
|
||||
|
||||
def load_item(self, index):
|
||||
video_name = self.video_names[index]
|
||||
all_frames = [f"{str(i).zfill(5)}.jpg" for i in range(self.video_dict[video_name])]
|
||||
all_masks = create_random_shape_with_random_motion(
|
||||
len(all_frames), imageHeight=self.h, imageWidth=self.w)
|
||||
ref_index = get_ref_index(len(all_frames), self.sample_length)
|
||||
# read video frames
|
||||
frames = []
|
||||
masks = []
|
||||
for idx in ref_index:
|
||||
img = ZipReader.imread('{}/{}/JPEGImages/{}.zip'.format(
|
||||
self.args['data_root'], self.args['name'], video_name), all_frames[idx]).convert('RGB')
|
||||
img = img.resize(self.size)
|
||||
frames.append(img)
|
||||
masks.append(all_masks[idx])
|
||||
if self.split == 'train':
|
||||
frames = GroupRandomHorizontalFlip()(frames)
|
||||
# To tensors
|
||||
frame_tensors = self._to_tensors(frames)*2.0 - 1.0
|
||||
mask_tensors = self._to_tensors(masks)
|
||||
return frame_tensors, mask_tensors
|
||||
|
||||
|
||||
def get_ref_index(length, sample_length):
|
||||
if random.uniform(0, 1) > 0.5:
|
||||
ref_index = random.sample(range(length), sample_length)
|
||||
ref_index.sort()
|
||||
else:
|
||||
pivot = random.randint(0, length-sample_length)
|
||||
ref_index = [pivot+i for i in range(sample_length)]
|
||||
return ref_index
|
||||
@@ -1,53 +0,0 @@
|
||||
import os
|
||||
import io
|
||||
import re
|
||||
import subprocess
|
||||
import logging
|
||||
import random
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
|
||||
def get_world_size():
|
||||
"""Find OMPI world size without calling mpi functions
|
||||
:rtype: int
|
||||
"""
|
||||
if os.environ.get('PMI_SIZE') is not None:
|
||||
return int(os.environ.get('PMI_SIZE') or 1)
|
||||
elif os.environ.get('OMPI_COMM_WORLD_SIZE') is not None:
|
||||
return int(os.environ.get('OMPI_COMM_WORLD_SIZE') or 1)
|
||||
else:
|
||||
return torch.cuda.device_count()
|
||||
|
||||
|
||||
def get_global_rank():
|
||||
"""Find OMPI world rank without calling mpi functions
|
||||
:rtype: int
|
||||
"""
|
||||
if os.environ.get('PMI_RANK') is not None:
|
||||
return int(os.environ.get('PMI_RANK') or 0)
|
||||
elif os.environ.get('OMPI_COMM_WORLD_RANK') is not None:
|
||||
return int(os.environ.get('OMPI_COMM_WORLD_RANK') or 0)
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
def get_local_rank():
|
||||
"""Find OMPI local rank without calling mpi functions
|
||||
:rtype: int
|
||||
"""
|
||||
if os.environ.get('MPI_LOCALRANKID') is not None:
|
||||
return int(os.environ.get('MPI_LOCALRANKID') or 0)
|
||||
elif os.environ.get('OMPI_COMM_WORLD_LOCAL_RANK') is not None:
|
||||
return int(os.environ.get('OMPI_COMM_WORLD_LOCAL_RANK') or 0)
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
def get_master_ip():
|
||||
if os.environ.get('AZ_BATCH_MASTER_NODE') is not None:
|
||||
return os.environ.get('AZ_BATCH_MASTER_NODE').split(':')[0]
|
||||
elif os.environ.get('AZ_BATCHAI_MPI_MASTER_NODE') is not None:
|
||||
return os.environ.get('AZ_BATCHAI_MPI_MASTER_NODE')
|
||||
else:
|
||||
return "127.0.0.1"
|
||||
@@ -1,44 +0,0 @@
|
||||
import torch
|
||||
import os
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torchvision.models as models
|
||||
|
||||
|
||||
class AdversarialLoss(nn.Module):
|
||||
r"""
|
||||
Adversarial loss
|
||||
https://arxiv.org/abs/1711.10337
|
||||
"""
|
||||
|
||||
def __init__(self, type='nsgan', target_real_label=1.0, target_fake_label=0.0):
|
||||
r"""
|
||||
type = nsgan | lsgan | hinge
|
||||
"""
|
||||
super(AdversarialLoss, self).__init__()
|
||||
self.type = type
|
||||
self.register_buffer('real_label', torch.tensor(target_real_label))
|
||||
self.register_buffer('fake_label', torch.tensor(target_fake_label))
|
||||
|
||||
if type == 'nsgan':
|
||||
self.criterion = nn.BCELoss()
|
||||
elif type == 'lsgan':
|
||||
self.criterion = nn.MSELoss()
|
||||
elif type == 'hinge':
|
||||
self.criterion = nn.ReLU()
|
||||
|
||||
def __call__(self, outputs, is_real, is_disc=None):
|
||||
if self.type == 'hinge':
|
||||
if is_disc:
|
||||
if is_real:
|
||||
outputs = -outputs
|
||||
return self.criterion(1 + outputs).mean()
|
||||
else:
|
||||
return (-outputs).mean()
|
||||
else:
|
||||
labels = (self.real_label if is_real else self.fake_label).expand_as(
|
||||
outputs)
|
||||
loss = self.criterion(outputs, labels)
|
||||
return loss
|
||||
|
||||
|
||||
@@ -1,267 +0,0 @@
|
||||
"""
|
||||
Spectral Normalization from https://arxiv.org/abs/1802.05957
|
||||
"""
|
||||
import torch
|
||||
from torch.nn.functional import normalize
|
||||
|
||||
|
||||
class SpectralNorm(object):
|
||||
# Invariant before and after each forward call:
|
||||
# u = normalize(W @ v)
|
||||
# NB: At initialization, this invariant is not enforced
|
||||
|
||||
_version = 1
|
||||
# At version 1:
|
||||
# made `W` not a buffer,
|
||||
# added `v` as a buffer, and
|
||||
# made eval mode use `W = u @ W_orig @ v` rather than the stored `W`.
|
||||
|
||||
def __init__(self, name='weight', n_power_iterations=1, dim=0, eps=1e-12):
|
||||
self.name = name
|
||||
self.dim = dim
|
||||
if n_power_iterations <= 0:
|
||||
raise ValueError('Expected n_power_iterations to be positive, but '
|
||||
'got n_power_iterations={}'.format(n_power_iterations))
|
||||
self.n_power_iterations = n_power_iterations
|
||||
self.eps = eps
|
||||
|
||||
def reshape_weight_to_matrix(self, weight):
|
||||
weight_mat = weight
|
||||
if self.dim != 0:
|
||||
# permute dim to front
|
||||
weight_mat = weight_mat.permute(self.dim,
|
||||
*[d for d in range(weight_mat.dim()) if d != self.dim])
|
||||
height = weight_mat.size(0)
|
||||
return weight_mat.reshape(height, -1)
|
||||
|
||||
def compute_weight(self, module, do_power_iteration):
|
||||
# NB: If `do_power_iteration` is set, the `u` and `v` vectors are
|
||||
# updated in power iteration **in-place**. This is very important
|
||||
# because in `DataParallel` forward, the vectors (being buffers) are
|
||||
# broadcast from the parallelized module to each module replica,
|
||||
# which is a new module object created on the fly. And each replica
|
||||
# runs its own spectral norm power iteration. So simply assigning
|
||||
# the updated vectors to the module this function runs on will cause
|
||||
# the update to be lost forever. And the next time the parallelized
|
||||
# module is replicated, the same randomly initialized vectors are
|
||||
# broadcast and used!
|
||||
#
|
||||
# Therefore, to make the change propagate back, we rely on two
|
||||
# important behaviors (also enforced via tests):
|
||||
# 1. `DataParallel` doesn't clone storage if the broadcast tensor
|
||||
# is already on correct device; and it makes sure that the
|
||||
# parallelized module is already on `device[0]`.
|
||||
# 2. If the out tensor in `out=` kwarg has correct shape, it will
|
||||
# just fill in the values.
|
||||
# Therefore, since the same power iteration is performed on all
|
||||
# devices, simply updating the tensors in-place will make sure that
|
||||
# the module replica on `device[0]` will update the _u vector on the
|
||||
# parallized module (by shared storage).
|
||||
#
|
||||
# However, after we update `u` and `v` in-place, we need to **clone**
|
||||
# them before using them to normalize the weight. This is to support
|
||||
# backproping through two forward passes, e.g., the common pattern in
|
||||
# GAN training: loss = D(real) - D(fake). Otherwise, engine will
|
||||
# complain that variables needed to do backward for the first forward
|
||||
# (i.e., the `u` and `v` vectors) are changed in the second forward.
|
||||
weight = getattr(module, self.name + '_orig')
|
||||
u = getattr(module, self.name + '_u')
|
||||
v = getattr(module, self.name + '_v')
|
||||
weight_mat = self.reshape_weight_to_matrix(weight)
|
||||
|
||||
if do_power_iteration:
|
||||
with torch.no_grad():
|
||||
for _ in range(self.n_power_iterations):
|
||||
# Spectral norm of weight equals to `u^T W v`, where `u` and `v`
|
||||
# are the first left and right singular vectors.
|
||||
# This power iteration produces approximations of `u` and `v`.
|
||||
v = normalize(torch.mv(weight_mat.t(), u), dim=0, eps=self.eps, out=v)
|
||||
u = normalize(torch.mv(weight_mat, v), dim=0, eps=self.eps, out=u)
|
||||
if self.n_power_iterations > 0:
|
||||
# See above on why we need to clone
|
||||
u = u.clone()
|
||||
v = v.clone()
|
||||
|
||||
sigma = torch.dot(u, torch.mv(weight_mat, v))
|
||||
weight = weight / sigma
|
||||
return weight
|
||||
|
||||
def remove(self, module):
|
||||
with torch.no_grad():
|
||||
weight = self.compute_weight(module, do_power_iteration=False)
|
||||
delattr(module, self.name)
|
||||
delattr(module, self.name + '_u')
|
||||
delattr(module, self.name + '_v')
|
||||
delattr(module, self.name + '_orig')
|
||||
module.register_parameter(self.name, torch.nn.Parameter(weight.detach()))
|
||||
|
||||
def __call__(self, module, inputs):
|
||||
setattr(module, self.name, self.compute_weight(module, do_power_iteration=module.training))
|
||||
|
||||
def _solve_v_and_rescale(self, weight_mat, u, target_sigma):
|
||||
# Tries to returns a vector `v` s.t. `u = normalize(W @ v)`
|
||||
# (the invariant at top of this class) and `u @ W @ v = sigma`.
|
||||
# This uses pinverse in case W^T W is not invertible.
|
||||
v = torch.chain_matmul(weight_mat.t().mm(weight_mat).pinverse(), weight_mat.t(), u.unsqueeze(1)).squeeze(1)
|
||||
return v.mul_(target_sigma / torch.dot(u, torch.mv(weight_mat, v)))
|
||||
|
||||
@staticmethod
|
||||
def apply(module, name, n_power_iterations, dim, eps):
|
||||
for k, hook in module._forward_pre_hooks.items():
|
||||
if isinstance(hook, SpectralNorm) and hook.name == name:
|
||||
raise RuntimeError("Cannot register two spectral_norm hooks on "
|
||||
"the same parameter {}".format(name))
|
||||
|
||||
fn = SpectralNorm(name, n_power_iterations, dim, eps)
|
||||
weight = module._parameters[name]
|
||||
|
||||
with torch.no_grad():
|
||||
weight_mat = fn.reshape_weight_to_matrix(weight)
|
||||
|
||||
h, w = weight_mat.size()
|
||||
# randomly initialize `u` and `v`
|
||||
u = normalize(weight.new_empty(h).normal_(0, 1), dim=0, eps=fn.eps)
|
||||
v = normalize(weight.new_empty(w).normal_(0, 1), dim=0, eps=fn.eps)
|
||||
|
||||
delattr(module, fn.name)
|
||||
module.register_parameter(fn.name + "_orig", weight)
|
||||
# We still need to assign weight back as fn.name because all sorts of
|
||||
# things may assume that it exists, e.g., when initializing weights.
|
||||
# However, we can't directly assign as it could be an nn.Parameter and
|
||||
# gets added as a parameter. Instead, we register weight.data as a plain
|
||||
# attribute.
|
||||
setattr(module, fn.name, weight.data)
|
||||
module.register_buffer(fn.name + "_u", u)
|
||||
module.register_buffer(fn.name + "_v", v)
|
||||
|
||||
module.register_forward_pre_hook(fn)
|
||||
|
||||
module._register_state_dict_hook(SpectralNormStateDictHook(fn))
|
||||
module._register_load_state_dict_pre_hook(SpectralNormLoadStateDictPreHook(fn))
|
||||
return fn
|
||||
|
||||
|
||||
# This is a top level class because Py2 pickle doesn't like inner class nor an
|
||||
# instancemethod.
|
||||
class SpectralNormLoadStateDictPreHook(object):
|
||||
# See docstring of SpectralNorm._version on the changes to spectral_norm.
|
||||
def __init__(self, fn):
|
||||
self.fn = fn
|
||||
|
||||
# For state_dict with version None, (assuming that it has gone through at
|
||||
# least one training forward), we have
|
||||
#
|
||||
# u = normalize(W_orig @ v)
|
||||
# W = W_orig / sigma, where sigma = u @ W_orig @ v
|
||||
#
|
||||
# To compute `v`, we solve `W_orig @ x = u`, and let
|
||||
# v = x / (u @ W_orig @ x) * (W / W_orig).
|
||||
def __call__(self, state_dict, prefix, local_metadata, strict,
|
||||
missing_keys, unexpected_keys, error_msgs):
|
||||
fn = self.fn
|
||||
version = local_metadata.get('spectral_norm', {}).get(fn.name + '.version', None)
|
||||
if version is None or version < 1:
|
||||
with torch.no_grad():
|
||||
weight_orig = state_dict[prefix + fn.name + '_orig']
|
||||
# weight = state_dict.pop(prefix + fn.name)
|
||||
# sigma = (weight_orig / weight).mean()
|
||||
weight_mat = fn.reshape_weight_to_matrix(weight_orig)
|
||||
u = state_dict[prefix + fn.name + '_u']
|
||||
# v = fn._solve_v_and_rescale(weight_mat, u, sigma)
|
||||
# state_dict[prefix + fn.name + '_v'] = v
|
||||
|
||||
|
||||
# This is a top level class because Py2 pickle doesn't like inner class nor an
|
||||
# instancemethod.
|
||||
class SpectralNormStateDictHook(object):
|
||||
# See docstring of SpectralNorm._version on the changes to spectral_norm.
|
||||
def __init__(self, fn):
|
||||
self.fn = fn
|
||||
|
||||
def __call__(self, module, state_dict, prefix, local_metadata):
|
||||
if 'spectral_norm' not in local_metadata:
|
||||
local_metadata['spectral_norm'] = {}
|
||||
key = self.fn.name + '.version'
|
||||
if key in local_metadata['spectral_norm']:
|
||||
raise RuntimeError("Unexpected key in metadata['spectral_norm']: {}".format(key))
|
||||
local_metadata['spectral_norm'][key] = self.fn._version
|
||||
|
||||
|
||||
def spectral_norm(module, name='weight', n_power_iterations=1, eps=1e-12, dim=None):
|
||||
r"""Applies spectral normalization to a parameter in the given module.
|
||||
|
||||
.. math::
|
||||
\mathbf{W}_{SN} = \dfrac{\mathbf{W}}{\sigma(\mathbf{W})},
|
||||
\sigma(\mathbf{W}) = \max_{\mathbf{h}: \mathbf{h} \ne 0} \dfrac{\|\mathbf{W} \mathbf{h}\|_2}{\|\mathbf{h}\|_2}
|
||||
|
||||
Spectral normalization stabilizes the training of discriminators (critics)
|
||||
in Generative Adversarial Networks (GANs) by rescaling the weight tensor
|
||||
with spectral norm :math:`\sigma` of the weight matrix calculated using
|
||||
power iteration method. If the dimension of the weight tensor is greater
|
||||
than 2, it is reshaped to 2D in power iteration method to get spectral
|
||||
norm. This is implemented via a hook that calculates spectral norm and
|
||||
rescales weight before every :meth:`~Module.forward` call.
|
||||
|
||||
See `Spectral Normalization for Generative Adversarial Networks`_ .
|
||||
|
||||
.. _`Spectral Normalization for Generative Adversarial Networks`: https://arxiv.org/abs/1802.05957
|
||||
|
||||
Args:
|
||||
module (nn.Module): containing module
|
||||
name (str, optional): name of weight parameter
|
||||
n_power_iterations (int, optional): number of power iterations to
|
||||
calculate spectral norm
|
||||
eps (float, optional): epsilon for numerical stability in
|
||||
calculating norms
|
||||
dim (int, optional): dimension corresponding to number of outputs,
|
||||
the default is ``0``, except for modules that are instances of
|
||||
ConvTranspose{1,2,3}d, when it is ``1``
|
||||
|
||||
Returns:
|
||||
The original module with the spectral norm hook
|
||||
|
||||
Example::
|
||||
|
||||
>>> m = spectral_norm(nn.Linear(20, 40))
|
||||
>>> m
|
||||
Linear(in_features=20, out_features=40, bias=True)
|
||||
>>> m.weight_u.size()
|
||||
torch.Size([40])
|
||||
|
||||
"""
|
||||
if dim is None:
|
||||
if isinstance(module, (torch.nn.ConvTranspose1d,
|
||||
torch.nn.ConvTranspose2d,
|
||||
torch.nn.ConvTranspose3d)):
|
||||
dim = 1
|
||||
else:
|
||||
dim = 0
|
||||
SpectralNorm.apply(module, name, n_power_iterations, dim, eps)
|
||||
return module
|
||||
|
||||
|
||||
def remove_spectral_norm(module, name='weight'):
|
||||
r"""Removes the spectral normalization reparameterization from a module.
|
||||
|
||||
Args:
|
||||
module (Module): containing module
|
||||
name (str, optional): name of weight parameter
|
||||
|
||||
Example:
|
||||
>>> m = spectral_norm(nn.Linear(40, 10))
|
||||
>>> remove_spectral_norm(m)
|
||||
"""
|
||||
for k, hook in module._forward_pre_hooks.items():
|
||||
if isinstance(hook, SpectralNorm) and hook.name == name:
|
||||
hook.remove(module)
|
||||
del module._forward_pre_hooks[k]
|
||||
return module
|
||||
|
||||
raise ValueError("spectral_norm of '{}' not found in {}".format(
|
||||
name, module))
|
||||
|
||||
|
||||
def use_spectral_norm(module, use_sn=False):
|
||||
if use_sn:
|
||||
return spectral_norm(module)
|
||||
return module
|
||||
@@ -1,272 +0,0 @@
|
||||
import os
|
||||
import cv2
|
||||
import time
|
||||
import math
|
||||
import glob
|
||||
from tqdm import tqdm
|
||||
import shutil
|
||||
import importlib
|
||||
import datetime
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
from math import log10
|
||||
|
||||
from functools import partial
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.optim as optim
|
||||
import torch.nn.functional as F
|
||||
from torch.utils.data import DataLoader
|
||||
from torch.utils.data.distributed import DistributedSampler
|
||||
from torch.nn.parallel import DistributedDataParallel as DDP
|
||||
from tensorboardX import SummaryWriter
|
||||
from torchvision.utils import make_grid, save_image
|
||||
import torch.distributed as dist
|
||||
|
||||
from core.dataset import Dataset
|
||||
from core.loss import AdversarialLoss
|
||||
|
||||
|
||||
class Trainer():
|
||||
def __init__(self, config, debug=False):
|
||||
self.config = config
|
||||
self.epoch = 0
|
||||
self.iteration = 0
|
||||
if debug:
|
||||
self.config['trainer']['save_freq'] = 5
|
||||
self.config['trainer']['valid_freq'] = 5
|
||||
self.config['trainer']['iterations'] = 5
|
||||
|
||||
# setup data set and data loader
|
||||
self.train_dataset = Dataset(config['data_loader'], split='train', debug=debug)
|
||||
self.train_sampler = None
|
||||
self.train_args = config['trainer']
|
||||
if config['distributed']:
|
||||
self.train_sampler = DistributedSampler(
|
||||
self.train_dataset,
|
||||
num_replicas=config['world_size'],
|
||||
rank=config['global_rank'])
|
||||
self.train_loader = DataLoader(
|
||||
self.train_dataset,
|
||||
batch_size=self.train_args['batch_size'] // config['world_size'],
|
||||
shuffle=(self.train_sampler is None),
|
||||
num_workers=self.train_args['num_workers'],
|
||||
sampler=self.train_sampler)
|
||||
|
||||
# set loss functions
|
||||
self.adversarial_loss = AdversarialLoss(type=self.config['losses']['GAN_LOSS'])
|
||||
self.adversarial_loss = self.adversarial_loss.to(self.config['device'])
|
||||
self.l1_loss = nn.L1Loss()
|
||||
|
||||
# setup models including generator and discriminator
|
||||
net = importlib.import_module('model.'+config['model'])
|
||||
self.netG = net.InpaintGenerator()
|
||||
self.netG = self.netG.to(self.config['device'])
|
||||
self.netD = net.Discriminator(
|
||||
in_channels=3, use_sigmoid=config['losses']['GAN_LOSS'] != 'hinge')
|
||||
self.netD = self.netD.to(self.config['device'])
|
||||
self.optimG = torch.optim.Adam(
|
||||
self.netG.parameters(),
|
||||
lr=config['trainer']['lr'],
|
||||
betas=(self.config['trainer']['beta1'], self.config['trainer']['beta2']))
|
||||
self.optimD = torch.optim.Adam(
|
||||
self.netD.parameters(),
|
||||
lr=config['trainer']['lr'],
|
||||
betas=(self.config['trainer']['beta1'], self.config['trainer']['beta2']))
|
||||
self.load()
|
||||
|
||||
if config['distributed']:
|
||||
self.netG = DDP(
|
||||
self.netG,
|
||||
device_ids=[self.config['local_rank']],
|
||||
output_device=self.config['local_rank'],
|
||||
broadcast_buffers=True,
|
||||
find_unused_parameters=False)
|
||||
self.netD = DDP(
|
||||
self.netD,
|
||||
device_ids=[self.config['local_rank']],
|
||||
output_device=self.config['local_rank'],
|
||||
broadcast_buffers=True,
|
||||
find_unused_parameters=False)
|
||||
|
||||
# set summary writer
|
||||
self.dis_writer = None
|
||||
self.gen_writer = None
|
||||
self.summary = {}
|
||||
if self.config['global_rank'] == 0 or (not config['distributed']):
|
||||
self.dis_writer = SummaryWriter(
|
||||
os.path.join(config['save_dir'], 'dis'))
|
||||
self.gen_writer = SummaryWriter(
|
||||
os.path.join(config['save_dir'], 'gen'))
|
||||
|
||||
# get current learning rate
|
||||
def get_lr(self):
|
||||
return self.optimG.param_groups[0]['lr']
|
||||
|
||||
# learning rate scheduler, step
|
||||
def adjust_learning_rate(self):
|
||||
decay = 0.1**(min(self.iteration,
|
||||
self.config['trainer']['niter_steady']) // self.config['trainer']['niter'])
|
||||
new_lr = self.config['trainer']['lr'] * decay
|
||||
if new_lr != self.get_lr():
|
||||
for param_group in self.optimG.param_groups:
|
||||
param_group['lr'] = new_lr
|
||||
for param_group in self.optimD.param_groups:
|
||||
param_group['lr'] = new_lr
|
||||
|
||||
# add summary
|
||||
def add_summary(self, writer, name, val):
|
||||
if name not in self.summary:
|
||||
self.summary[name] = 0
|
||||
self.summary[name] += val
|
||||
if writer is not None and self.iteration % 100 == 0:
|
||||
writer.add_scalar(name, self.summary[name]/100, self.iteration)
|
||||
self.summary[name] = 0
|
||||
|
||||
# load netG and netD
|
||||
def load(self):
|
||||
model_path = self.config['save_dir']
|
||||
if os.path.isfile(os.path.join(model_path, 'latest.ckpt')):
|
||||
latest_epoch = open(os.path.join(
|
||||
model_path, 'latest.ckpt'), 'r').read().splitlines()[-1]
|
||||
else:
|
||||
ckpts = [os.path.basename(i).split('.pth')[0] for i in glob.glob(
|
||||
os.path.join(model_path, '*.pth'))]
|
||||
ckpts.sort()
|
||||
latest_epoch = ckpts[-1] if len(ckpts) > 0 else None
|
||||
if latest_epoch is not None:
|
||||
gen_path = os.path.join(
|
||||
model_path, 'gen_{}.pth'.format(str(latest_epoch).zfill(5)))
|
||||
dis_path = os.path.join(
|
||||
model_path, 'dis_{}.pth'.format(str(latest_epoch).zfill(5)))
|
||||
opt_path = os.path.join(
|
||||
model_path, 'opt_{}.pth'.format(str(latest_epoch).zfill(5)))
|
||||
if self.config['global_rank'] == 0:
|
||||
print('Loading model from {}...'.format(gen_path))
|
||||
data = torch.load(gen_path, map_location=self.config['device'])
|
||||
self.netG.load_state_dict(data['netG'])
|
||||
data = torch.load(dis_path, map_location=self.config['device'])
|
||||
self.netD.load_state_dict(data['netD'])
|
||||
data = torch.load(opt_path, map_location=self.config['device'])
|
||||
self.optimG.load_state_dict(data['optimG'])
|
||||
self.optimD.load_state_dict(data['optimD'])
|
||||
self.epoch = data['epoch']
|
||||
self.iteration = data['iteration']
|
||||
else:
|
||||
if self.config['global_rank'] == 0:
|
||||
print(
|
||||
'Warnning: There is no trained model found. An initialized model will be used.')
|
||||
|
||||
# save parameters every eval_epoch
|
||||
def save(self, it):
|
||||
if self.config['global_rank'] == 0:
|
||||
gen_path = os.path.join(
|
||||
self.config['save_dir'], 'gen_{}.pth'.format(str(it).zfill(5)))
|
||||
dis_path = os.path.join(
|
||||
self.config['save_dir'], 'dis_{}.pth'.format(str(it).zfill(5)))
|
||||
opt_path = os.path.join(
|
||||
self.config['save_dir'], 'opt_{}.pth'.format(str(it).zfill(5)))
|
||||
print('\nsaving model to {} ...'.format(gen_path))
|
||||
if isinstance(self.netG, torch.nn.DataParallel) or isinstance(self.netG, DDP):
|
||||
netG = self.netG.module
|
||||
netD = self.netD.module
|
||||
else:
|
||||
netG = self.netG
|
||||
netD = self.netD
|
||||
torch.save({'netG': netG.state_dict()}, gen_path)
|
||||
torch.save({'netD': netD.state_dict()}, dis_path)
|
||||
torch.save({'epoch': self.epoch,
|
||||
'iteration': self.iteration,
|
||||
'optimG': self.optimG.state_dict(),
|
||||
'optimD': self.optimD.state_dict()}, opt_path)
|
||||
os.system('echo {} > {}'.format(str(it).zfill(5),
|
||||
os.path.join(self.config['save_dir'], 'latest.ckpt')))
|
||||
|
||||
# train entry
|
||||
def train(self):
|
||||
pbar = range(int(self.train_args['iterations']))
|
||||
if self.config['global_rank'] == 0:
|
||||
pbar = tqdm(pbar, initial=self.iteration, dynamic_ncols=True, smoothing=0.01)
|
||||
|
||||
while True:
|
||||
self.epoch += 1
|
||||
if self.config['distributed']:
|
||||
self.train_sampler.set_epoch(self.epoch)
|
||||
|
||||
self._train_epoch(pbar)
|
||||
if self.iteration > self.train_args['iterations']:
|
||||
break
|
||||
print('\nEnd training....')
|
||||
|
||||
# process input and calculate loss every training epoch
|
||||
def _train_epoch(self, pbar):
|
||||
device = self.config['device']
|
||||
|
||||
for frames, masks in self.train_loader:
|
||||
self.adjust_learning_rate()
|
||||
self.iteration += 1
|
||||
|
||||
frames, masks = frames.to(device), masks.to(device)
|
||||
b, t, c, h, w = frames.size()
|
||||
masked_frame = (frames * (1 - masks).float())
|
||||
pred_img = self.netG(masked_frame, masks)
|
||||
frames = frames.view(b*t, c, h, w)
|
||||
masks = masks.view(b*t, 1, h, w)
|
||||
comp_img = frames*(1.-masks) + masks*pred_img
|
||||
|
||||
gen_loss = 0
|
||||
dis_loss = 0
|
||||
|
||||
# discriminator adversarial loss
|
||||
real_vid_feat = self.netD(frames)
|
||||
fake_vid_feat = self.netD(comp_img.detach())
|
||||
dis_real_loss = self.adversarial_loss(real_vid_feat, True, True)
|
||||
dis_fake_loss = self.adversarial_loss(fake_vid_feat, False, True)
|
||||
dis_loss += (dis_real_loss + dis_fake_loss) / 2
|
||||
self.add_summary(
|
||||
self.dis_writer, 'loss/dis_vid_fake', dis_fake_loss.item())
|
||||
self.add_summary(
|
||||
self.dis_writer, 'loss/dis_vid_real', dis_real_loss.item())
|
||||
self.optimD.zero_grad()
|
||||
dis_loss.backward()
|
||||
self.optimD.step()
|
||||
|
||||
# generator adversarial loss
|
||||
gen_vid_feat = self.netD(comp_img)
|
||||
gan_loss = self.adversarial_loss(gen_vid_feat, True, False)
|
||||
gan_loss = gan_loss * self.config['losses']['adversarial_weight']
|
||||
gen_loss += gan_loss
|
||||
self.add_summary(
|
||||
self.gen_writer, 'loss/gan_loss', gan_loss.item())
|
||||
|
||||
# generator l1 loss
|
||||
hole_loss = self.l1_loss(pred_img*masks, frames*masks)
|
||||
hole_loss = hole_loss / torch.mean(masks) * self.config['losses']['hole_weight']
|
||||
gen_loss += hole_loss
|
||||
self.add_summary(
|
||||
self.gen_writer, 'loss/hole_loss', hole_loss.item())
|
||||
|
||||
valid_loss = self.l1_loss(pred_img*(1-masks), frames*(1-masks))
|
||||
valid_loss = valid_loss / torch.mean(1-masks) * self.config['losses']['valid_weight']
|
||||
gen_loss += valid_loss
|
||||
self.add_summary(
|
||||
self.gen_writer, 'loss/valid_loss', valid_loss.item())
|
||||
|
||||
self.optimG.zero_grad()
|
||||
gen_loss.backward()
|
||||
self.optimG.step()
|
||||
|
||||
# console logs
|
||||
if self.config['global_rank'] == 0:
|
||||
pbar.update(1)
|
||||
pbar.set_description((
|
||||
f"d: {dis_loss.item():.3f}; g: {gan_loss.item():.3f};"
|
||||
f"hole: {hole_loss.item():.3f}; valid: {valid_loss.item():.3f}")
|
||||
)
|
||||
|
||||
# saving models
|
||||
if self.iteration % self.train_args['save_freq'] == 0:
|
||||
self.save(int(self.iteration//self.train_args['save_freq']))
|
||||
if self.iteration > self.train_args['iterations']:
|
||||
break
|
||||
|
||||
@@ -1,253 +0,0 @@
|
||||
import matplotlib.patches as patches
|
||||
from matplotlib.path import Path
|
||||
import os
|
||||
import sys
|
||||
import io
|
||||
import cv2
|
||||
import time
|
||||
import argparse
|
||||
import shutil
|
||||
import random
|
||||
import zipfile
|
||||
from glob import glob
|
||||
import math
|
||||
import numpy as np
|
||||
import torch.nn.functional as F
|
||||
import torchvision.transforms as transforms
|
||||
from PIL import Image, ImageOps, ImageDraw, ImageFilter
|
||||
|
||||
import torch
|
||||
import torchvision
|
||||
import torch.nn as nn
|
||||
import torch.distributed as dist
|
||||
|
||||
import matplotlib
|
||||
from matplotlib import pyplot as plt
|
||||
matplotlib.use('agg')
|
||||
|
||||
|
||||
# #####################################################
|
||||
# #####################################################
|
||||
|
||||
class ZipReader(object):
|
||||
file_dict = dict()
|
||||
|
||||
def __init__(self):
|
||||
super(ZipReader, self).__init__()
|
||||
|
||||
@staticmethod
|
||||
def build_file_dict(path):
|
||||
file_dict = ZipReader.file_dict
|
||||
if path in file_dict:
|
||||
return file_dict[path]
|
||||
else:
|
||||
file_handle = zipfile.ZipFile(path, 'r')
|
||||
file_dict[path] = file_handle
|
||||
return file_dict[path]
|
||||
|
||||
@staticmethod
|
||||
def imread(path, image_name):
|
||||
zfile = ZipReader.build_file_dict(path)
|
||||
data = zfile.read(image_name)
|
||||
im = Image.open(io.BytesIO(data))
|
||||
return im
|
||||
|
||||
# ###########################################################################
|
||||
# ###########################################################################
|
||||
|
||||
|
||||
class GroupRandomHorizontalFlip(object):
|
||||
"""Randomly horizontally flips the given PIL.Image with a probability of 0.5
|
||||
"""
|
||||
|
||||
def __init__(self, is_flow=False):
|
||||
self.is_flow = is_flow
|
||||
|
||||
def __call__(self, img_group, is_flow=False):
|
||||
v = random.random()
|
||||
if v < 0.5:
|
||||
ret = [img.transpose(Image.FLIP_LEFT_RIGHT) for img in img_group]
|
||||
if self.is_flow:
|
||||
for i in range(0, len(ret), 2):
|
||||
# invert flow pixel values when flipping
|
||||
ret[i] = ImageOps.invert(ret[i])
|
||||
return ret
|
||||
else:
|
||||
return img_group
|
||||
|
||||
|
||||
class Stack(object):
|
||||
def __init__(self, roll=False):
|
||||
self.roll = roll
|
||||
|
||||
def __call__(self, img_group):
|
||||
mode = img_group[0].mode
|
||||
if mode == '1':
|
||||
img_group = [img.convert('L') for img in img_group]
|
||||
mode = 'L'
|
||||
if mode == 'L':
|
||||
return np.stack([np.expand_dims(x, 2) for x in img_group], axis=2)
|
||||
elif mode == 'RGB':
|
||||
if self.roll:
|
||||
return np.stack([np.array(x)[:, :, ::-1] for x in img_group], axis=2)
|
||||
else:
|
||||
return np.stack(img_group, axis=2)
|
||||
else:
|
||||
raise NotImplementedError(f"Image mode {mode}")
|
||||
|
||||
|
||||
class ToTorchFormatTensor(object):
|
||||
""" Converts a PIL.Image (RGB) or numpy.ndarray (H x W x C) in the range [0, 255]
|
||||
to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] """
|
||||
|
||||
def __init__(self, div=True):
|
||||
self.div = div
|
||||
|
||||
def __call__(self, pic):
|
||||
if isinstance(pic, np.ndarray):
|
||||
# numpy img: [L, C, H, W]
|
||||
img = torch.from_numpy(pic).permute(2, 3, 0, 1).contiguous()
|
||||
else:
|
||||
# handle PIL Image
|
||||
img = torch.ByteTensor(
|
||||
torch.ByteStorage.from_buffer(pic.tobytes()))
|
||||
img = img.view(pic.size[1], pic.size[0], len(pic.mode))
|
||||
# put it from HWC to CHW format
|
||||
# yikes, this transpose takes 80% of the loading time/CPU
|
||||
img = img.transpose(0, 1).transpose(0, 2).contiguous()
|
||||
img = img.float().div(255) if self.div else img.float()
|
||||
return img
|
||||
|
||||
|
||||
# ##########################################
|
||||
# ##########################################
|
||||
|
||||
def create_random_shape_with_random_motion(video_length, imageHeight=240, imageWidth=432):
|
||||
# get a random shape
|
||||
height = random.randint(imageHeight//3, imageHeight-1)
|
||||
width = random.randint(imageWidth//3, imageWidth-1)
|
||||
edge_num = random.randint(6, 8)
|
||||
ratio = random.randint(6, 8)/10
|
||||
region = get_random_shape(
|
||||
edge_num=edge_num, ratio=ratio, height=height, width=width)
|
||||
region_width, region_height = region.size
|
||||
# get random position
|
||||
x, y = random.randint(
|
||||
0, imageHeight-region_height), random.randint(0, imageWidth-region_width)
|
||||
velocity = get_random_velocity(max_speed=3)
|
||||
m = Image.fromarray(np.zeros((imageHeight, imageWidth)).astype(np.uint8))
|
||||
m.paste(region, (y, x, y+region.size[0], x+region.size[1]))
|
||||
masks = [m.convert('L')]
|
||||
# return fixed masks
|
||||
if random.uniform(0, 1) > 0.5:
|
||||
return masks*video_length
|
||||
# return moving masks
|
||||
for _ in range(video_length-1):
|
||||
x, y, velocity = random_move_control_points(
|
||||
x, y, imageHeight, imageWidth, velocity, region.size, maxLineAcceleration=(3, 0.5), maxInitSpeed=3)
|
||||
m = Image.fromarray(
|
||||
np.zeros((imageHeight, imageWidth)).astype(np.uint8))
|
||||
m.paste(region, (y, x, y+region.size[0], x+region.size[1]))
|
||||
masks.append(m.convert('L'))
|
||||
return masks
|
||||
|
||||
|
||||
def get_random_shape(edge_num=9, ratio=0.7, width=432, height=240):
|
||||
'''
|
||||
There is the initial point and 3 points per cubic bezier curve.
|
||||
Thus, the curve will only pass though n points, which will be the sharp edges.
|
||||
The other 2 modify the shape of the bezier curve.
|
||||
edge_num, Number of possibly sharp edges
|
||||
points_num, number of points in the Path
|
||||
ratio, (0, 1) magnitude of the perturbation from the unit circle,
|
||||
'''
|
||||
points_num = edge_num*3 + 1
|
||||
angles = np.linspace(0, 2*np.pi, points_num)
|
||||
codes = np.full(points_num, Path.CURVE4)
|
||||
codes[0] = Path.MOVETO
|
||||
# Using this instad of Path.CLOSEPOLY avoids an innecessary straight line
|
||||
verts = np.stack((np.cos(angles), np.sin(angles))).T * \
|
||||
(2*ratio*np.random.random(points_num)+1-ratio)[:, None]
|
||||
verts[-1, :] = verts[0, :]
|
||||
path = Path(verts, codes)
|
||||
# draw paths into images
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
patch = patches.PathPatch(path, facecolor='black', lw=2)
|
||||
ax.add_patch(patch)
|
||||
ax.set_xlim(np.min(verts)*1.1, np.max(verts)*1.1)
|
||||
ax.set_ylim(np.min(verts)*1.1, np.max(verts)*1.1)
|
||||
ax.axis('off') # removes the axis to leave only the shape
|
||||
fig.canvas.draw()
|
||||
# convert plt images into numpy images
|
||||
data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
|
||||
data = data.reshape((fig.canvas.get_width_height()[::-1] + (3,)))
|
||||
plt.close(fig)
|
||||
# postprocess
|
||||
data = cv2.resize(data, (width, height))[:, :, 0]
|
||||
data = (1 - np.array(data > 0).astype(np.uint8))*255
|
||||
corrdinates = np.where(data > 0)
|
||||
xmin, xmax, ymin, ymax = np.min(corrdinates[0]), np.max(
|
||||
corrdinates[0]), np.min(corrdinates[1]), np.max(corrdinates[1])
|
||||
region = Image.fromarray(data).crop((ymin, xmin, ymax, xmax))
|
||||
return region
|
||||
|
||||
|
||||
def random_accelerate(velocity, maxAcceleration, dist='uniform'):
|
||||
speed, angle = velocity
|
||||
d_speed, d_angle = maxAcceleration
|
||||
if dist == 'uniform':
|
||||
speed += np.random.uniform(-d_speed, d_speed)
|
||||
angle += np.random.uniform(-d_angle, d_angle)
|
||||
elif dist == 'guassian':
|
||||
speed += np.random.normal(0, d_speed / 2)
|
||||
angle += np.random.normal(0, d_angle / 2)
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
f'Distribution type {dist} is not supported.')
|
||||
return (speed, angle)
|
||||
|
||||
|
||||
def get_random_velocity(max_speed=3, dist='uniform'):
|
||||
if dist == 'uniform':
|
||||
speed = np.random.uniform(max_speed)
|
||||
elif dist == 'guassian':
|
||||
speed = np.abs(np.random.normal(0, max_speed / 2))
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
f'Distribution type {dist} is not supported.')
|
||||
angle = np.random.uniform(0, 2 * np.pi)
|
||||
return (speed, angle)
|
||||
|
||||
|
||||
def random_move_control_points(X, Y, imageHeight, imageWidth, lineVelocity, region_size, maxLineAcceleration=(3, 0.5), maxInitSpeed=3):
|
||||
region_width, region_height = region_size
|
||||
speed, angle = lineVelocity
|
||||
X += int(speed * np.cos(angle))
|
||||
Y += int(speed * np.sin(angle))
|
||||
lineVelocity = random_accelerate(
|
||||
lineVelocity, maxLineAcceleration, dist='guassian')
|
||||
if ((X > imageHeight - region_height) or (X < 0) or (Y > imageWidth - region_width) or (Y < 0)):
|
||||
lineVelocity = get_random_velocity(maxInitSpeed, dist='guassian')
|
||||
new_X = np.clip(X, 0, imageHeight - region_height)
|
||||
new_Y = np.clip(Y, 0, imageWidth - region_width)
|
||||
return new_X, new_Y, lineVelocity
|
||||
|
||||
|
||||
|
||||
# ##############################################
|
||||
# ##############################################
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
trials = 10
|
||||
for _ in range(trials):
|
||||
video_length = 10
|
||||
# The returned masks are either stationary (50%) or moving (50%)
|
||||
masks = create_random_shape_with_random_motion(
|
||||
video_length, imageHeight=240, imageWidth=432)
|
||||
|
||||
for m in masks:
|
||||
cv2.imshow('mask', np.array(m))
|
||||
cv2.waitKey(500)
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
{"bear": 82, "bike-packing": 69, "blackswan": 50, "bmx-bumps": 90, "bmx-trees": 80, "boat": 75, "boxing-fisheye": 87, "breakdance": 84, "breakdance-flare": 71, "bus": 80, "camel": 90, "car-roundabout": 75, "car-shadow": 40, "car-turn": 80, "cat-girl": 89, "classic-car": 63, "color-run": 84, "cows": 104, "crossing": 52, "dance-jump": 60, "dance-twirl": 90, "dancing": 62, "disc-jockey": 76, "dog": 60, "dog-agility": 25, "dog-gooses": 86, "dogs-jump": 66, "dogs-scale": 83, "drift-chicane": 52, "drift-straight": 50, "drift-turn": 64, "drone": 91, "elephant": 80, "flamingo": 80, "goat": 90, "gold-fish": 78, "hike": 80, "hockey": 75, "horsejump-high": 50, "horsejump-low": 60, "india": 81, "judo": 34, "kid-football": 68, "kite-surf": 50, "kite-walk": 80, "koala": 100, "lab-coat": 47, "lady-running": 65, "libby": 49, "lindy-hop": 73, "loading": 50, "longboard": 52, "lucia": 70, "mallard-fly": 70, "mallard-water": 80, "mbike-trick": 79, "miami-surf": 70, "motocross-bumps": 60, "motocross-jump": 40, "motorbike": 43, "night-race": 46, "paragliding": 70, "paragliding-launch": 80, "parkour": 100, "pigs": 79, "planes-water": 38, "rallye": 50, "rhino": 90, "rollerblade": 35, "schoolgirls": 80, "scooter-black": 43, "scooter-board": 91, "scooter-gray": 75, "sheep": 68, "shooting": 40, "skate-park": 80, "snowboard": 66, "soapbox": 99, "soccerball": 48, "stroller": 91, "stunt": 71, "surf": 55, "swing": 60, "tennis": 70, "tractor-sand": 76, "train": 80, "tuk-tuk": 59, "upside-down": 65, "varanus-cage": 67, "walking": 72}
|
||||
@@ -1 +0,0 @@
|
||||
{"baseball": 90, "basketball-game": 77, "bears-ball": 78, "bmx-rider": 85, "butterfly": 80, "car-competition": 66, "cat": 52, "chairlift": 99, "circus": 73, "city-ride": 70, "crafting": 45, "curling": 76, "dog-competition": 85, "dolphins-show": 74, "dribbling": 49, "drone-flying": 70, "ducks": 75, "elephant-hyenas": 55, "giraffes": 88, "gym-ball": 69, "helicopter-landing": 77, "horse-race": 80, "horses-kids": 78, "hurdles-race": 55, "ice-hockey": 52, "jet-ski": 83, "juggling-selfie": 78, "kayak-race": 63, "kids-robot": 75, "landing": 35, "luggage": 83, "mantaray": 73, "marbles": 70, "mascot": 78, "mermaid": 78, "monster-trucks": 99, "motorbike-indoors": 79, "motorbike-race": 88, "music-band": 87, "obstacles": 81, "obstacles-race": 48, "peacock": 75, "plane-exhibition": 73, "puppet": 100, "robot-battle": 85, "robotic-arm": 82, "rodeo": 85, "sea-turtle": 90, "skydiving-jumping": 75, "snowboard-race": 75, "snowboard-sand": 55, "surfer": 80, "swimmer": 86, "table-tennis": 70, "tram": 84, "trucks-race": 78, "twist-dance": 83, "volleyball-beach": 73, "water-slide": 88, "weightlifting": 90}
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@@ -1,131 +0,0 @@
|
||||
name: sttn
|
||||
channels:
|
||||
- defaults
|
||||
dependencies:
|
||||
- _libgcc_mutex=0.1=main
|
||||
- ca-certificates=2020.7.22=0
|
||||
- certifi=2020.6.20=py36_0
|
||||
- cudatoolkit=10.1.243=h6bb024c_0
|
||||
- libedit=3.1.20181209=hc058e9b_0
|
||||
- libffi=3.2.1=hd88cf55_4
|
||||
- libgcc-ng=9.1.0=hdf63c60_0
|
||||
- libstdcxx-ng=9.1.0=hdf63c60_0
|
||||
- ncurses=6.2=he6710b0_1
|
||||
- openssl=1.0.2u=h7b6447c_0
|
||||
- pip=20.0.2=py36_3
|
||||
- python=3.6.3=h6c0c0dc_5
|
||||
- readline=7.0=h7b6447c_5
|
||||
- setuptools=47.1.1=py36_0
|
||||
- sqlite=3.31.1=h62c20be_1
|
||||
- tk=8.6.8=hbc83047_0
|
||||
- wheel=0.34.2=py36_0
|
||||
- xz=5.2.5=h7b6447c_0
|
||||
- zlib=1.2.11=h7b6447c_3
|
||||
- pip:
|
||||
- absl-py==0.9.0
|
||||
- appdirs==1.4.4
|
||||
- astor==0.8.1
|
||||
- attrs==19.3.0
|
||||
- backcall==0.2.0
|
||||
- bleach==3.1.5
|
||||
- cachetools==4.1.0
|
||||
- chainer==7.7.0
|
||||
- chardet==3.0.4
|
||||
- cpython==0.0.6
|
||||
- cupy==7.7.0
|
||||
- cycler==0.10.0
|
||||
- cython==0.29.21
|
||||
- decorator==4.4.2
|
||||
- defusedxml==0.6.0
|
||||
- entrypoints==0.3
|
||||
- fastrlock==0.5
|
||||
- filelock==3.0.12
|
||||
- future==0.18.2
|
||||
- gast==0.3.3
|
||||
- google-auth==1.17.2
|
||||
- google-auth-oauthlib==0.4.1
|
||||
- grpcio==1.29.0
|
||||
- h5py==2.10.0
|
||||
- idna==2.9
|
||||
- imageio==2.8.0
|
||||
- importlib-metadata==1.6.1
|
||||
- ipykernel==5.3.0
|
||||
- ipython==7.15.0
|
||||
- ipython-genutils==0.2.0
|
||||
- jedi==0.17.0
|
||||
- jinja2==2.11.2
|
||||
- joblib==0.16.0
|
||||
- jsonschema==3.2.0
|
||||
- jupyter-client==6.1.3
|
||||
- jupyter-core==4.6.3
|
||||
- keras-applications==1.0.8
|
||||
- keras-preprocessing==1.1.2
|
||||
- kiwisolver==1.2.0
|
||||
- lmdb==0.98
|
||||
- mako==1.1.3
|
||||
- markdown==3.2.2
|
||||
- markupsafe==1.1.1
|
||||
- matplotlib==3.2.1
|
||||
- mistune==0.8.4
|
||||
- nbconvert==5.6.1
|
||||
- nbformat==5.0.7
|
||||
- networkx==2.4
|
||||
- nose==1.3.7
|
||||
- notebook==6.0.3
|
||||
- numpy==1.18.5
|
||||
- oauthlib==3.1.0
|
||||
- opencv-python==4.2.0.34
|
||||
- packaging==20.4
|
||||
- pandas==1.1.0
|
||||
- pandocfilters==1.4.2
|
||||
- parso==0.7.0
|
||||
- pexpect==4.8.0
|
||||
- pickleshare==0.7.5
|
||||
- pillow==7.1.2
|
||||
- prometheus-client==0.8.0
|
||||
- prompt-toolkit==3.0.5
|
||||
- protobuf==3.12.2
|
||||
- ptyprocess==0.6.0
|
||||
- pyasn1==0.4.8
|
||||
- pyasn1-modules==0.2.8
|
||||
- pybind11==2.5.0
|
||||
- pycuda==2019.1.2
|
||||
- pygments==2.6.1
|
||||
- pymongo==3.11.0
|
||||
- pyparsing==2.4.7
|
||||
- pypi==2.1
|
||||
- pyrsistent==0.16.0
|
||||
- python-dateutil==2.8.1
|
||||
- pytools==2020.3
|
||||
- pywavelets==1.1.1
|
||||
- pyyaml==5.3.1
|
||||
- pyzmq==19.0.1
|
||||
- requests==2.23.0
|
||||
- requests-oauthlib==1.3.0
|
||||
- rsa==4.6
|
||||
- scikit-image==0.17.2
|
||||
- scikit-learn==0.23.2
|
||||
- scipy==1.4.1
|
||||
- send2trash==1.5.0
|
||||
- six==1.15.0
|
||||
- tensorboard==2.2.2
|
||||
- tensorboard-plugin-wit==1.6.0.post3
|
||||
- tensorboardx==2.0
|
||||
- tensorflow-gpu==1.12.0
|
||||
- termcolor==1.1.0
|
||||
- terminado==0.8.3
|
||||
- testpath==0.4.4
|
||||
- threadpoolctl==2.1.0
|
||||
- tifffile==2020.6.3
|
||||
- torch==1.1.0
|
||||
- torchvision==0.3.0
|
||||
- tornado==6.0.4
|
||||
- traitlets==4.3.3
|
||||
- tqdm==4.49.0
|
||||
- typing-extensions==3.7.4.2
|
||||
- urllib3==1.25.9
|
||||
- wcwidth==0.2.4
|
||||
- webencodings==0.5.1
|
||||
- werkzeug==1.0.1
|
||||
- zipp==3.1.0
|
||||
|
||||
@@ -1,304 +0,0 @@
|
||||
''' Spatial-Temporal Transformer Networks
|
||||
'''
|
||||
import numpy as np
|
||||
import math
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torchvision.models as models
|
||||
from core.spectral_norm import spectral_norm as _spectral_norm
|
||||
|
||||
|
||||
class BaseNetwork(nn.Module):
|
||||
def __init__(self):
|
||||
super(BaseNetwork, self).__init__()
|
||||
|
||||
def print_network(self):
|
||||
if isinstance(self, list):
|
||||
self = self[0]
|
||||
num_params = 0
|
||||
for param in self.parameters():
|
||||
num_params += param.numel()
|
||||
print('Network [%s] was created. Total number of parameters: %.1f million. '
|
||||
'To see the architecture, do print(network).' % (type(self).__name__, num_params / 1000000))
|
||||
|
||||
def init_weights(self, init_type='normal', gain=0.02):
|
||||
'''
|
||||
initialize network's weights
|
||||
init_type: normal | xavier | kaiming | orthogonal
|
||||
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/9451e70673400885567d08a9e97ade2524c700d0/models/networks.py#L39
|
||||
'''
|
||||
def init_func(m):
|
||||
classname = m.__class__.__name__
|
||||
if classname.find('InstanceNorm2d') != -1:
|
||||
if hasattr(m, 'weight') and m.weight is not None:
|
||||
nn.init.constant_(m.weight.data, 1.0)
|
||||
if hasattr(m, 'bias') and m.bias is not None:
|
||||
nn.init.constant_(m.bias.data, 0.0)
|
||||
elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
|
||||
if init_type == 'normal':
|
||||
nn.init.normal_(m.weight.data, 0.0, gain)
|
||||
elif init_type == 'xavier':
|
||||
nn.init.xavier_normal_(m.weight.data, gain=gain)
|
||||
elif init_type == 'xavier_uniform':
|
||||
nn.init.xavier_uniform_(m.weight.data, gain=1.0)
|
||||
elif init_type == 'kaiming':
|
||||
nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
|
||||
elif init_type == 'orthogonal':
|
||||
nn.init.orthogonal_(m.weight.data, gain=gain)
|
||||
elif init_type == 'none': # uses pytorch's default init method
|
||||
m.reset_parameters()
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
'initialization method [%s] is not implemented' % init_type)
|
||||
if hasattr(m, 'bias') and m.bias is not None:
|
||||
nn.init.constant_(m.bias.data, 0.0)
|
||||
|
||||
self.apply(init_func)
|
||||
|
||||
# propagate to children
|
||||
for m in self.children():
|
||||
if hasattr(m, 'init_weights'):
|
||||
m.init_weights(init_type, gain)
|
||||
|
||||
|
||||
class InpaintGenerator(BaseNetwork):
|
||||
def __init__(self, init_weights=True):
|
||||
super(InpaintGenerator, self).__init__()
|
||||
channel = 256
|
||||
stack_num = 8
|
||||
patchsize = [(108, 60), (36, 20), (18, 10), (9, 5)]
|
||||
blocks = []
|
||||
for _ in range(stack_num):
|
||||
blocks.append(TransformerBlock(patchsize, hidden=channel))
|
||||
self.transformer = nn.Sequential(*blocks)
|
||||
|
||||
self.encoder = nn.Sequential(
|
||||
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(128, channel, kernel_size=3, stride=1, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
)
|
||||
|
||||
# decoder: decode frames from features
|
||||
self.decoder = nn.Sequential(
|
||||
deconv(channel, 128, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
deconv(64, 64, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(64, 3, kernel_size=3, stride=1, padding=1)
|
||||
)
|
||||
|
||||
if init_weights:
|
||||
self.init_weights()
|
||||
|
||||
def forward(self, masked_frames, masks):
|
||||
# extracting features
|
||||
b, t, c, h, w = masked_frames.size()
|
||||
masks = masks.view(b*t, 1, h, w)
|
||||
enc_feat = self.encoder(masked_frames.view(b*t, c, h, w))
|
||||
_, c, h, w = enc_feat.size()
|
||||
masks = F.interpolate(masks, scale_factor=1.0/4)
|
||||
enc_feat = self.transformer(
|
||||
{'x': enc_feat, 'm': masks, 'b': b, 'c': c})['x']
|
||||
output = self.decoder(enc_feat)
|
||||
output = torch.tanh(output)
|
||||
return output
|
||||
|
||||
def infer(self, feat, masks):
|
||||
t, c, h, w = masks.size()
|
||||
masks = masks.view(t, c, h, w)
|
||||
masks = F.interpolate(masks, scale_factor=1.0/4)
|
||||
t, c, _, _ = feat.size()
|
||||
enc_feat = self.transformer(
|
||||
{'x': feat, 'm': masks, 'b': 1, 'c': c})['x']
|
||||
return enc_feat
|
||||
|
||||
|
||||
class deconv(nn.Module):
|
||||
def __init__(self, input_channel, output_channel, kernel_size=3, padding=0):
|
||||
super().__init__()
|
||||
self.conv = nn.Conv2d(input_channel, output_channel,
|
||||
kernel_size=kernel_size, stride=1, padding=padding)
|
||||
|
||||
def forward(self, x):
|
||||
x = F.interpolate(x, scale_factor=2, mode='bilinear',
|
||||
align_corners=True)
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
# #############################################################################
|
||||
# ############################# Transformer ##################################
|
||||
# #############################################################################
|
||||
|
||||
|
||||
class Attention(nn.Module):
|
||||
"""
|
||||
Compute 'Scaled Dot Product Attention
|
||||
"""
|
||||
|
||||
def forward(self, query, key, value, m):
|
||||
scores = torch.matmul(query, key.transpose(-2, -1)
|
||||
) / math.sqrt(query.size(-1))
|
||||
scores.masked_fill(m, -1e9)
|
||||
p_attn = F.softmax(scores, dim=-1)
|
||||
p_val = torch.matmul(p_attn, value)
|
||||
return p_val, p_attn
|
||||
|
||||
|
||||
class MultiHeadedAttention(nn.Module):
|
||||
"""
|
||||
Take in model size and number of heads.
|
||||
"""
|
||||
|
||||
def __init__(self, patchsize, d_model):
|
||||
super().__init__()
|
||||
self.patchsize = patchsize
|
||||
self.query_embedding = nn.Conv2d(
|
||||
d_model, d_model, kernel_size=1, padding=0)
|
||||
self.value_embedding = nn.Conv2d(
|
||||
d_model, d_model, kernel_size=1, padding=0)
|
||||
self.key_embedding = nn.Conv2d(
|
||||
d_model, d_model, kernel_size=1, padding=0)
|
||||
self.output_linear = nn.Sequential(
|
||||
nn.Conv2d(d_model, d_model, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True))
|
||||
self.attention = Attention()
|
||||
|
||||
def forward(self, x, m, b, c):
|
||||
bt, _, h, w = x.size()
|
||||
t = bt // b
|
||||
d_k = c // len(self.patchsize)
|
||||
output = []
|
||||
_query = self.query_embedding(x)
|
||||
_key = self.key_embedding(x)
|
||||
_value = self.value_embedding(x)
|
||||
for (width, height), query, key, value in zip(self.patchsize,
|
||||
torch.chunk(_query, len(self.patchsize), dim=1), torch.chunk(
|
||||
_key, len(self.patchsize), dim=1),
|
||||
torch.chunk(_value, len(self.patchsize), dim=1)):
|
||||
out_w, out_h = w // width, h // height
|
||||
mm = m.view(b, t, 1, out_h, height, out_w, width)
|
||||
mm = mm.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, height*width)
|
||||
mm = (mm.mean(-1) > 0.5).unsqueeze(1).repeat(1, t*out_h*out_w, 1)
|
||||
# 1) embedding and reshape
|
||||
query = query.view(b, t, d_k, out_h, height, out_w, width)
|
||||
query = query.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, d_k*height*width)
|
||||
key = key.view(b, t, d_k, out_h, height, out_w, width)
|
||||
key = key.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, d_k*height*width)
|
||||
value = value.view(b, t, d_k, out_h, height, out_w, width)
|
||||
value = value.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, d_k*height*width)
|
||||
'''
|
||||
# 2) Apply attention on all the projected vectors in batch.
|
||||
tmp1 = []
|
||||
for q,k,v in zip(torch.chunk(query, b, dim=0), torch.chunk(key, b, dim=0), torch.chunk(value, b, dim=0)):
|
||||
y, _ = self.attention(q.unsqueeze(0), k.unsqueeze(0), v.unsqueeze(0))
|
||||
tmp1.append(y)
|
||||
y = torch.cat(tmp1,1)
|
||||
'''
|
||||
y, _ = self.attention(query, key, value, mm)
|
||||
# 3) "Concat" using a view and apply a final linear.
|
||||
y = y.view(b, t, out_h, out_w, d_k, height, width)
|
||||
y = y.permute(0, 1, 4, 2, 5, 3, 6).contiguous().view(bt, d_k, h, w)
|
||||
output.append(y)
|
||||
output = torch.cat(output, 1)
|
||||
x = self.output_linear(output)
|
||||
return x
|
||||
|
||||
|
||||
# Standard 2 layerd FFN of transformer
|
||||
class FeedForward(nn.Module):
|
||||
def __init__(self, d_model):
|
||||
super(FeedForward, self).__init__()
|
||||
# We set d_ff as a default to 2048
|
||||
self.conv = nn.Sequential(
|
||||
nn.Conv2d(d_model, d_model, kernel_size=3, padding=2, dilation=2),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(d_model, d_model, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True))
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class TransformerBlock(nn.Module):
|
||||
"""
|
||||
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
|
||||
"""
|
||||
|
||||
def __init__(self, patchsize, hidden=128):
|
||||
super().__init__()
|
||||
self.attention = MultiHeadedAttention(patchsize, d_model=hidden)
|
||||
self.feed_forward = FeedForward(hidden)
|
||||
|
||||
def forward(self, x):
|
||||
x, m, b, c = x['x'], x['m'], x['b'], x['c']
|
||||
x = x + self.attention(x, m, b, c)
|
||||
x = x + self.feed_forward(x)
|
||||
return {'x': x, 'm': m, 'b': b, 'c': c}
|
||||
|
||||
|
||||
# ######################################################################
|
||||
# ######################################################################
|
||||
|
||||
|
||||
class Discriminator(BaseNetwork):
|
||||
def __init__(self, in_channels=3, use_sigmoid=False, use_spectral_norm=True, init_weights=True):
|
||||
super(Discriminator, self).__init__()
|
||||
self.use_sigmoid = use_sigmoid
|
||||
nf = 64
|
||||
|
||||
self.conv = nn.Sequential(
|
||||
spectral_norm(nn.Conv3d(in_channels=in_channels, out_channels=nf*1, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=1, bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(64, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf*1, nf*2, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(128, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf * 2, nf * 4, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(256, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf * 4, nf * 4, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(256, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf * 4, nf * 4, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(256, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv3d(nf * 4, nf * 4, kernel_size=(3, 5, 5),
|
||||
stride=(1, 2, 2), padding=(1, 2, 2))
|
||||
)
|
||||
|
||||
if init_weights:
|
||||
self.init_weights()
|
||||
|
||||
def forward(self, xs):
|
||||
# T, C, H, W = xs.shape
|
||||
xs_t = torch.transpose(xs, 0, 1)
|
||||
xs_t = xs_t.unsqueeze(0) # B, C, T, H, W
|
||||
feat = self.conv(xs_t)
|
||||
if self.use_sigmoid:
|
||||
feat = torch.sigmoid(feat)
|
||||
out = torch.transpose(feat, 1, 2) # B, T, C, H, W
|
||||
return out
|
||||
|
||||
|
||||
def spectral_norm(module, mode=True):
|
||||
if mode:
|
||||
return _spectral_norm(module)
|
||||
return module
|
||||
@@ -1,314 +0,0 @@
|
||||
''' Spatial-Temporal Transformer Networks
|
||||
'''
|
||||
import numpy as np
|
||||
import math
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torchvision.models as models
|
||||
from core.spectral_norm import spectral_norm as _spectral_norm
|
||||
|
||||
|
||||
class BaseNetwork(nn.Module):
|
||||
def __init__(self):
|
||||
super(BaseNetwork, self).__init__()
|
||||
|
||||
def print_network(self):
|
||||
if isinstance(self, list):
|
||||
self = self[0]
|
||||
num_params = 0
|
||||
for param in self.parameters():
|
||||
num_params += param.numel()
|
||||
print('Network [%s] was created. Total number of parameters: %.1f million. '
|
||||
'To see the architecture, do print(network).' % (type(self).__name__, num_params / 1000000))
|
||||
|
||||
def init_weights(self, init_type='normal', gain=0.02):
|
||||
'''
|
||||
initialize network's weights
|
||||
init_type: normal | xavier | kaiming | orthogonal
|
||||
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/9451e70673400885567d08a9e97ade2524c700d0/models/networks.py#L39
|
||||
'''
|
||||
def init_func(m):
|
||||
classname = m.__class__.__name__
|
||||
if classname.find('InstanceNorm2d') != -1:
|
||||
if hasattr(m, 'weight') and m.weight is not None:
|
||||
nn.init.constant_(m.weight.data, 1.0)
|
||||
if hasattr(m, 'bias') and m.bias is not None:
|
||||
nn.init.constant_(m.bias.data, 0.0)
|
||||
elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
|
||||
if init_type == 'normal':
|
||||
nn.init.normal_(m.weight.data, 0.0, gain)
|
||||
elif init_type == 'xavier':
|
||||
nn.init.xavier_normal_(m.weight.data, gain=gain)
|
||||
elif init_type == 'xavier_uniform':
|
||||
nn.init.xavier_uniform_(m.weight.data, gain=1.0)
|
||||
elif init_type == 'kaiming':
|
||||
nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
|
||||
elif init_type == 'orthogonal':
|
||||
nn.init.orthogonal_(m.weight.data, gain=gain)
|
||||
elif init_type == 'none': # uses pytorch's default init method
|
||||
m.reset_parameters()
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
'initialization method [%s] is not implemented' % init_type)
|
||||
if hasattr(m, 'bias') and m.bias is not None:
|
||||
nn.init.constant_(m.bias.data, 0.0)
|
||||
|
||||
self.apply(init_func)
|
||||
|
||||
# propagate to children
|
||||
for m in self.children():
|
||||
if hasattr(m, 'init_weights'):
|
||||
m.init_weights(init_type, gain)
|
||||
|
||||
|
||||
class InpaintGenerator(BaseNetwork):
|
||||
def __init__(self, init_weights=True): # 1046
|
||||
super(InpaintGenerator, self).__init__()
|
||||
channel = 256
|
||||
stack_num = 8
|
||||
patchsize = [(108, 60), (36, 20), (18, 10), (9, 5)]
|
||||
blocks = []
|
||||
for _ in range(stack_num):
|
||||
blocks.append(TransformerBlock(patchsize, hidden=channel))
|
||||
self.transformer = nn.Sequential(*blocks)
|
||||
|
||||
self.encoder = nn.Sequential(
|
||||
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(128, channel, kernel_size=3, stride=1, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
)
|
||||
|
||||
# decoder: decode image from features
|
||||
self.decoder = nn.Sequential(
|
||||
deconv(channel, 128, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
deconv(64, 64, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(64, 3, kernel_size=3, stride=1, padding=1)
|
||||
)
|
||||
|
||||
if init_weights:
|
||||
self.init_weights()
|
||||
|
||||
def forward(self, masked_frames, masks):
|
||||
# extracting features
|
||||
b, t, c, h, w = masked_frames.size()
|
||||
masks = masks.view(b*t, 1, h, w)
|
||||
enc_feat = self.encoder(masked_frames.view(b*t, c, h, w))
|
||||
_, c, h, w = enc_feat.size()
|
||||
masks = F.interpolate(masks, scale_factor=1.0/4)
|
||||
enc_feat = self.transformer(
|
||||
{'x': enc_feat, 'm': masks, 'b': b, 'c': c})['x']
|
||||
output = self.decoder(enc_feat)
|
||||
output = torch.tanh(output)
|
||||
return output
|
||||
|
||||
def infer(self, feat, masks):
|
||||
t, c, h, w = masks.size()
|
||||
masks = masks.view(t, c, h, w)
|
||||
masks = F.interpolate(masks, scale_factor=1.0/4)
|
||||
t, c, _, _ = feat.size()
|
||||
output = self.transformer({'x': feat, 'm': masks, 'b': 1, 'c': c})
|
||||
enc_feat = output['x']
|
||||
attn = output['attn']
|
||||
mm = output['smm']
|
||||
return enc_feat, attn, mm
|
||||
|
||||
|
||||
class deconv(nn.Module):
|
||||
def __init__(self, input_channel, output_channel, kernel_size=3, padding=0):
|
||||
super().__init__()
|
||||
self.conv = nn.Conv2d(input_channel, output_channel,
|
||||
kernel_size=kernel_size, stride=1, padding=padding)
|
||||
|
||||
def forward(self, x):
|
||||
x = F.interpolate(x, scale_factor=2, mode='bilinear',
|
||||
align_corners=True)
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
# ##################################################
|
||||
# ################## Transformer ####################
|
||||
|
||||
|
||||
class Attention(nn.Module):
|
||||
"""
|
||||
Compute 'Scaled Dot Product Attention
|
||||
"""
|
||||
|
||||
def forward(self, query, key, value, m):
|
||||
scores = torch.matmul(query, key.transpose(-2, -1)
|
||||
) / math.sqrt(query.size(-1))
|
||||
scores.masked_fill(m, -1e9)
|
||||
p_attn = F.softmax(scores, dim=-1)
|
||||
p_val = torch.matmul(p_attn, value)
|
||||
return p_val, p_attn
|
||||
|
||||
|
||||
class MultiHeadedAttention(nn.Module):
|
||||
"""
|
||||
Take in model size and number of heads.
|
||||
"""
|
||||
|
||||
def __init__(self, patchsize, d_model):
|
||||
super().__init__()
|
||||
self.patchsize = patchsize
|
||||
self.query_embedding = nn.Conv2d(
|
||||
d_model, d_model, kernel_size=1, padding=0)
|
||||
self.value_embedding = nn.Conv2d(
|
||||
d_model, d_model, kernel_size=1, padding=0)
|
||||
self.key_embedding = nn.Conv2d(
|
||||
d_model, d_model, kernel_size=1, padding=0)
|
||||
self.output_linear = nn.Sequential(
|
||||
nn.Conv2d(d_model, d_model, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True))
|
||||
self.attention = Attention()
|
||||
|
||||
def forward(self, x, m, b, c):
|
||||
bt, _, h, w = x.size()
|
||||
t = bt // b
|
||||
d_k = c // len(self.patchsize)
|
||||
output = []
|
||||
_query = self.query_embedding(x)
|
||||
_key = self.key_embedding(x)
|
||||
_value = self.value_embedding(x)
|
||||
for (width, height), query, key, value in zip(self.patchsize,
|
||||
torch.chunk(_query, len(self.patchsize), dim=1), torch.chunk(
|
||||
_key, len(self.patchsize), dim=1),
|
||||
torch.chunk(_value, len(self.patchsize), dim=1)):
|
||||
out_w, out_h = w // width, h // height
|
||||
mm = m.view(b, t, 1, out_h, height, out_w, width)
|
||||
mm = mm.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, height*width)
|
||||
mm = (mm.mean(-1) > 0.5).unsqueeze(1).repeat(1, t*out_h*out_w, 1)
|
||||
# 1) embedding and reshape
|
||||
query = query.view(b, t, d_k, out_h, height, out_w, width)
|
||||
query = query.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, d_k*height*width)
|
||||
key = key.view(b, t, d_k, out_h, height, out_w, width)
|
||||
key = key.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, d_k*height*width)
|
||||
value = value.view(b, t, d_k, out_h, height, out_w, width)
|
||||
value = value.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(
|
||||
b, t*out_h*out_w, d_k*height*width)
|
||||
'''
|
||||
# 2) Apply attention on all the projected vectors in batch.
|
||||
tmp1 = []
|
||||
for q,k,v in zip(torch.chunk(query, b, dim=0), torch.chunk(key, b, dim=0), torch.chunk(value, b, dim=0)):
|
||||
y, _ = self.attention(q.unsqueeze(0), k.unsqueeze(0), v.unsqueeze(0))
|
||||
tmp1.append(y)
|
||||
y = torch.cat(tmp1,1)
|
||||
'''
|
||||
y, attn = self.attention(query, key, value, mm)
|
||||
|
||||
# return attention value for visualization
|
||||
# here we return the attention value of patchsize=18
|
||||
if width == 18:
|
||||
select_attn = attn.view(t, out_h*out_w, t, out_h, out_w)[0]
|
||||
# mm, [b, thw, thw]
|
||||
select_mm = mm[0].view(t*out_h*out_w, t, out_h, out_w)[0]
|
||||
|
||||
# 3) "Concat" using a view and apply a final linear.
|
||||
y = y.view(b, t, out_h, out_w, d_k, height, width)
|
||||
y = y.permute(0, 1, 4, 2, 5, 3, 6).contiguous().view(bt, d_k, h, w)
|
||||
output.append(y)
|
||||
output = torch.cat(output, 1)
|
||||
x = self.output_linear(output)
|
||||
return x, select_attn, select_mm
|
||||
|
||||
|
||||
# Standard 2 layerd FFN of transformer
|
||||
class FeedForward(nn.Module):
|
||||
def __init__(self, d_model):
|
||||
super(FeedForward, self).__init__()
|
||||
# We set d_ff as a default to 2048
|
||||
self.conv = nn.Sequential(
|
||||
nn.Conv2d(d_model, d_model, kernel_size=3, padding=2, dilation=2),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(d_model, d_model, kernel_size=3, padding=1),
|
||||
nn.LeakyReLU(0.2, inplace=True))
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class TransformerBlock(nn.Module):
|
||||
"""
|
||||
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
|
||||
"""
|
||||
|
||||
def __init__(self, patchsize, hidden=128):
|
||||
super().__init__()
|
||||
self.attention = MultiHeadedAttention(patchsize, d_model=hidden)
|
||||
self.feed_forward = FeedForward(hidden)
|
||||
|
||||
def forward(self, x):
|
||||
x, m, b, c = x['x'], x['m'], x['b'], x['c']
|
||||
val, attn, mm = self.attention(x, m, b, c)
|
||||
x = x + val
|
||||
x = x + self.feed_forward(x)
|
||||
return {'x': x, 'm': m, 'b': b, 'c': c, 'attn': attn, 'smm': mm}
|
||||
|
||||
|
||||
# ######################################################################
|
||||
# ######################################################################
|
||||
|
||||
|
||||
class Discriminator(BaseNetwork):
|
||||
def __init__(self, in_channels=3, use_sigmoid=False, use_spectral_norm=True, init_weights=True):
|
||||
super(Discriminator, self).__init__()
|
||||
self.use_sigmoid = use_sigmoid
|
||||
nf = 64
|
||||
|
||||
self.conv = nn.Sequential(
|
||||
spectral_norm(nn.Conv3d(in_channels=in_channels, out_channels=nf*1, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=1, bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(64, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf*1, nf*2, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(128, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf * 2, nf * 4, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(256, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf * 4, nf * 4, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(256, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv3d(nf * 4, nf * 4, kernel_size=(3, 5, 5), stride=(1, 2, 2),
|
||||
padding=(1, 2, 2), bias=not use_spectral_norm), use_spectral_norm),
|
||||
# nn.InstanceNorm2d(256, track_running_stats=False),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv3d(nf * 4, nf * 4, kernel_size=(3, 5, 5),
|
||||
stride=(1, 2, 2), padding=(1, 2, 2))
|
||||
)
|
||||
|
||||
if init_weights:
|
||||
self.init_weights()
|
||||
|
||||
def forward(self, xs):
|
||||
# T, C, H, W = xs.shape
|
||||
xs_t = torch.transpose(xs, 0, 1)
|
||||
xs_t = xs_t.unsqueeze(0) # B, C, T, H, W
|
||||
feat = self.conv(xs_t)
|
||||
if self.use_sigmoid:
|
||||
feat = torch.sigmoid(feat)
|
||||
out = torch.transpose(feat, 1, 2) # B, T, C, H, W
|
||||
return out
|
||||
|
||||
|
||||
def spectral_norm(module, mode=True):
|
||||
if mode:
|
||||
return _spectral_norm(module)
|
||||
return module
|
||||
@@ -1,149 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
import cv2
|
||||
import matplotlib.pyplot as plt
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
import math
|
||||
import time
|
||||
import importlib
|
||||
import os
|
||||
import argparse
|
||||
import copy
|
||||
import datetime
|
||||
import random
|
||||
import sys
|
||||
import json
|
||||
|
||||
import torch
|
||||
from torch.autograd import Variable
|
||||
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torch.nn.init as init
|
||||
import torch.utils.model_zoo as model_zoo
|
||||
from torchvision import models
|
||||
import torch.multiprocessing as mp
|
||||
from torchvision import transforms
|
||||
|
||||
# My libs
|
||||
from core.utils import Stack, ToTorchFormatTensor
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser(description="STTN")
|
||||
parser.add_argument("-v", "--video", type=str, required=True)
|
||||
parser.add_argument("-m", "--mask", type=str, required=True)
|
||||
parser.add_argument("-c", "--ckpt", type=str, required=True)
|
||||
parser.add_argument("--model", type=str, default='sttn')
|
||||
args = parser.parse_args()
|
||||
|
||||
|
||||
w, h = 432, 240
|
||||
ref_length = 10
|
||||
neighbor_stride = 5
|
||||
default_fps = 24
|
||||
|
||||
_to_tensors = transforms.Compose([
|
||||
Stack(),
|
||||
ToTorchFormatTensor()])
|
||||
|
||||
|
||||
# sample reference frames from the whole video
|
||||
def get_ref_index(neighbor_ids, length):
|
||||
ref_index = []
|
||||
for i in range(0, length, ref_length):
|
||||
if not i in neighbor_ids:
|
||||
ref_index.append(i)
|
||||
return ref_index
|
||||
|
||||
|
||||
# read frame-wise masks
|
||||
def read_mask(mpath):
|
||||
masks = []
|
||||
mnames = os.listdir(mpath)
|
||||
mnames.sort()
|
||||
for m in mnames:
|
||||
m = Image.open(os.path.join(mpath, m))
|
||||
m = m.resize((w, h), Image.NEAREST)
|
||||
m = np.array(m.convert('L'))
|
||||
m = np.array(m > 0).astype(np.uint8)
|
||||
m = cv2.dilate(m, cv2.getStructuringElement(
|
||||
cv2.MORPH_CROSS, (3, 3)), iterations=4)
|
||||
masks.append(Image.fromarray(m*255))
|
||||
return masks
|
||||
|
||||
|
||||
# read frames from video
|
||||
def read_frame_from_videos(vname):
|
||||
frames = []
|
||||
vidcap = cv2.VideoCapture(vname)
|
||||
success, image = vidcap.read()
|
||||
count = 0
|
||||
while success:
|
||||
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
|
||||
frames.append(image.resize((w,h)))
|
||||
success, image = vidcap.read()
|
||||
count += 1
|
||||
return frames
|
||||
|
||||
|
||||
def main_worker():
|
||||
# set up models
|
||||
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
|
||||
net = importlib.import_module('model.' + args.model)
|
||||
model = net.InpaintGenerator().to(device)
|
||||
model_path = args.ckpt
|
||||
data = torch.load(args.ckpt, map_location=device)
|
||||
model.load_state_dict(data['netG'])
|
||||
print('loading from: {}'.format(args.ckpt))
|
||||
model.eval()
|
||||
|
||||
# prepare datset, encode all frames into deep space
|
||||
frames = read_frame_from_videos(args.video)
|
||||
video_length = len(frames)
|
||||
feats = _to_tensors(frames).unsqueeze(0)*2-1
|
||||
frames = [np.array(f).astype(np.uint8) for f in frames]
|
||||
|
||||
masks = read_mask(args.mask)
|
||||
binary_masks = [np.expand_dims((np.array(m) != 0).astype(np.uint8), 2) for m in masks]
|
||||
masks = _to_tensors(masks).unsqueeze(0)
|
||||
feats, masks = feats.to(device), masks.to(device)
|
||||
comp_frames = [None]*video_length
|
||||
|
||||
with torch.no_grad():
|
||||
feats = model.encoder((feats*(1-masks).float()).view(video_length, 3, h, w))
|
||||
_, c, feat_h, feat_w = feats.size()
|
||||
feats = feats.view(1, video_length, c, feat_h, feat_w)
|
||||
print('loading videos and masks from: {}'.format(args.video))
|
||||
|
||||
# completing holes by spatial-temporal transformers
|
||||
for f in range(0, video_length, neighbor_stride):
|
||||
neighbor_ids = [i for i in range(max(0, f-neighbor_stride), min(video_length, f+neighbor_stride+1))]
|
||||
ref_ids = get_ref_index(neighbor_ids, video_length)
|
||||
with torch.no_grad():
|
||||
pred_feat = model.infer(
|
||||
feats[0, neighbor_ids+ref_ids, :, :, :], masks[0, neighbor_ids+ref_ids, :, :, :])
|
||||
pred_img = torch.tanh(model.decoder(
|
||||
pred_feat[:len(neighbor_ids), :, :, :])).detach()
|
||||
pred_img = (pred_img + 1) / 2
|
||||
pred_img = pred_img.cpu().permute(0, 2, 3, 1).numpy()*255
|
||||
for i in range(len(neighbor_ids)):
|
||||
idx = neighbor_ids[i]
|
||||
img = np.array(pred_img[i]).astype(
|
||||
np.uint8)*binary_masks[idx] + frames[idx] * (1-binary_masks[idx])
|
||||
if comp_frames[idx] is None:
|
||||
comp_frames[idx] = img
|
||||
else:
|
||||
comp_frames[idx] = comp_frames[idx].astype(
|
||||
np.float32)*0.5 + img.astype(np.float32)*0.5
|
||||
writer = cv2.VideoWriter(f"{args.mask}_result.mp4", cv2.VideoWriter_fourcc(*"mp4v"), default_fps, (w, h))
|
||||
for f in range(video_length):
|
||||
comp = np.array(comp_frames[f]).astype(
|
||||
np.uint8)*binary_masks[f] + frames[f] * (1-binary_masks[f])
|
||||
writer.write(cv2.cvtColor(np.array(comp).astype(np.uint8), cv2.COLOR_BGR2RGB))
|
||||
writer.release()
|
||||
print('Finish in {}'.format(f"{args.mask}_result.mp4"))
|
||||
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main_worker()
|
||||
@@ -1,79 +0,0 @@
|
||||
import os
|
||||
import json
|
||||
import argparse
|
||||
import datetime
|
||||
import numpy as np
|
||||
from shutil import copyfile
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
|
||||
from core.trainer import Trainer
|
||||
from core.dist import (
|
||||
get_world_size,
|
||||
get_local_rank,
|
||||
get_global_rank,
|
||||
get_master_ip,
|
||||
)
|
||||
|
||||
parser = argparse.ArgumentParser(description='STTN')
|
||||
parser.add_argument('-c', '--config', default='configs/youtube-vos.json', type=str)
|
||||
parser.add_argument('-m', '--model', default='sttn', type=str)
|
||||
parser.add_argument('-p', '--port', default='23455', type=str)
|
||||
parser.add_argument('-e', '--exam', action='store_true')
|
||||
args = parser.parse_args()
|
||||
|
||||
|
||||
def main_worker(rank, config):
|
||||
if 'local_rank' not in config:
|
||||
config['local_rank'] = config['global_rank'] = rank
|
||||
if config['distributed']:
|
||||
torch.cuda.set_device(int(config['local_rank']))
|
||||
torch.distributed.init_process_group(backend='nccl',
|
||||
init_method=config['init_method'],
|
||||
world_size=config['world_size'],
|
||||
rank=config['global_rank'],
|
||||
group_name='mtorch'
|
||||
)
|
||||
print('using GPU {}-{} for training'.format(
|
||||
int(config['global_rank']), int(config['local_rank'])))
|
||||
|
||||
config['save_dir'] = os.path.join(config['save_dir'], '{}_{}'.format(config['model'],
|
||||
os.path.basename(args.config).split('.')[0]))
|
||||
if torch.cuda.is_available():
|
||||
config['device'] = torch.device("cuda:{}".format(config['local_rank']))
|
||||
else:
|
||||
config['device'] = 'cpu'
|
||||
|
||||
if (not config['distributed']) or config['global_rank'] == 0:
|
||||
os.makedirs(config['save_dir'], exist_ok=True)
|
||||
config_path = os.path.join(
|
||||
config['save_dir'], config['config'].split('/')[-1])
|
||||
if not os.path.isfile(config_path):
|
||||
copyfile(config['config'], config_path)
|
||||
print('[**] create folder {}'.format(config['save_dir']))
|
||||
|
||||
trainer = Trainer(config, debug=args.exam)
|
||||
trainer.train()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# loading configs
|
||||
config = json.load(open(args.config))
|
||||
config['model'] = args.model
|
||||
config['config'] = args.config
|
||||
|
||||
# setting distributed configurations
|
||||
config['world_size'] = get_world_size()
|
||||
config['init_method'] = f"tcp://{get_master_ip()}:{args.port}"
|
||||
config['distributed'] = True if config['world_size'] > 1 else False
|
||||
|
||||
# setup distributed parallel training environments
|
||||
if get_master_ip() == "127.0.0.1":
|
||||
# manually launch distributed processes
|
||||
mp.spawn(main_worker, nprocs=config['world_size'], args=(config,))
|
||||
else:
|
||||
# multiple processes have been launched by openmpi
|
||||
config['local_rank'] = get_local_rank()
|
||||
config['global_rank'] = get_global_rank()
|
||||
main_worker(-1, config)
|
||||
@@ -55,6 +55,7 @@ class SubtitleDetect:
|
||||
|
||||
def find_subtitle_frame_no(self):
|
||||
video_cap = cv2.VideoCapture(self.video_path)
|
||||
frame_count = video_cap.get(cv2.CAP_PROP_FRAME_COUNT)
|
||||
current_frame_no = 0
|
||||
subtitle_frame_no_list = {}
|
||||
|
||||
@@ -80,6 +81,7 @@ class SubtitleDetect:
|
||||
else:
|
||||
temp_list.append((xmin, xmax, ymin, ymax))
|
||||
subtitle_frame_no_list[current_frame_no] = temp_list
|
||||
print(f'[字幕查找]{current_frame_no}/{int(frame_count)}')
|
||||
return subtitle_frame_no_list
|
||||
|
||||
|
||||
@@ -144,7 +146,7 @@ class SubtitleRemover:
|
||||
masks = self.create_mask(frame, sub_list[index])
|
||||
frame = self.inpaint_frame(frame, masks)
|
||||
self.video_writer.write(frame)
|
||||
print(f'{index}/{int(self.frame_count)}')
|
||||
print(f'[字幕去除]{index}/{int(self.frame_count)}')
|
||||
self.video_cap.release()
|
||||
self.video_writer.release()
|
||||
|
||||
|
||||
Binary file not shown.
Reference in New Issue
Block a user